搜索到
26
篇与
的结果
-

-
-
-
2022 在路上 西藏 四川 新疆 自驾 装备清单 物品清单摄影设备 DJI Air2 电池 *3 充电器 32G SD卡 Osmo Action 三脚架 车载固定吸盘 128G SD卡 Sony A6000 18-135镜头 32G大卡 三脚架 两块3T硬盘 读卡器 卡套 行车记录仪 *2 供电设备 逆变器 充电宝 1万毫安 * 2 迷你充电宝 锂电池 60V 60V转12v逆变器 线材 type-c 线 *3 DP诱骗线 * 1 快门线 USB转Sata USB分线器 车载及应急救援设备 车辆启动搭线 扳手螺丝刀 车载充气泵 逆变器 公路地图 防水火柴 绝缘胶带 警示牌 钳子 车载冰箱* 对讲机* 铁丝(防止防滑链脱落) 铁锹 洗漱 牙刷 毛巾 洗面奶 保湿 面膜 刮胡刀 防晒 面巾纸 湿纸巾 炊具 气炉 气罐转接头 高山气罐 *2 卡式炉气罐 * 10 烧水壶 锅 一次性碗 大 一次性碗 小 一次性筷子 水杯 药品 氧气 布洛芬 葡萄糖 速效救心丸 阿莫西林 泰诺 清凉油 绷带 花露水 驱蚊药 食品 红牛 * 10 口香糖一罐 咖啡罐装 冷冻咖啡 鸡蛋 牛奶一箱 大米 泡面一箱 矿泉水 两箱 榨菜 压缩并 盐 老干妈 火锅底料 (灵感来自徐云流浪中国) 露营装备 帐篷 天幕 蛋卷桌 椅子*1 防潮垫 瑜伽垫 手电筒 露营灯 羽绒被 毛毯 水袋 暖宝宝 压缩水桶 衣物 拖鞋 袜子 * 15 羽绒服 卫衣 * 3 牛仔裤 * 3 内裤 * 5 保暖内衣 雨衣 太阳镜 口罩*50 雨伞 证件 身份证 驾驶证 边防证 银行卡 * 为可选装备线路Plan A 滇藏线->318->阿里->317Plan B 新疆Plan C 甘南Plan D 川西车辆大保健 常规保养 检查胎压 检查备胎 检查左边边裙(维修过)
-
数据同步的一些思考与改进 数据同步的一些思考与改进背景闲的没事,自己写了个小网站,搭建在自己国外的VPS上,VPS内存极小(512M),而且还要跑点别的(你懂的),内存更紧张巴巴. 改造之前小网站用到了时髦的Redis,Rabbmitmq,Mysql,那时候阿里云的学生主机内存富足,装这么多中间件压力不大,可到了这样的小内存VPS上,一切都变得水土不服,索性啥中间件都不要了,数据库也不要了.没了数据库,网站的数据从哪里来?存在哪里? 文本形式持久化到本地磁盘?国外的VPS不比国内,可能哪天说不能访问就不能访问了,VPS的磁盘存储显然不踏实.同事给我建议了万能的Github,听过Github托管代码📜,托管静态页面🔮,托管女装大佬💃,但托管网站数据倒是第一次听说,于是我对网站架构进行了重新设计.Plan1 数据的同步小网站数据不多,10M左右,所有数据直接加载到内存中服务器也不会吃力,网站启动,自动从Github Clone数据,并定期把内存中的数据序列化后Push到Github.可以看到,整个过程中,好像没有磁盘啥事了,在我的眼里,Github就是一块延时略高的磁盘(其实延时也还好,国外的Github访问速度飞快).Plan2 同步的频率磁盘的读取速度和内存无法比,何况远程的Github,那么如果减少数据从内存到Github的同步开销呢?显然就是减少同步的频率.一小时同步一次,应该够了.但如果我的网站在这一小时挂了boom🌋,而数据还没来得及同步,那上次一同步到网站挂掉这个时间段内的数据不就没了吗?细思极恐😱!Plan3 多多不益善既然一小时一次不安全,那就一分钟同步一次!其实这样也是有问题的,小网站一般都是无人问津,如果以较高的频率进行数据同步,可以说绝大多数(用互联网的所法是百分之N个9)的数据同步都是没意义的,同时还增大了数据的同步开销,没准Github还会把我的账号给封了.Plan4 内存数据变更立即触发数据同步在我的网站中,有统一的数据访问层,只要数据访问层中的insert,update,delete处加入数据同步事件,即可实现一旦更新立即同步.这样是数据是安全了,可是一次访问请求往往伴随着多次数据更新,每更新一次同步一次,可能是最脑残🙈的做法吧.Question数据更改一次同步一次不合理,同步频率太低数据不安全,频率太高多数同步没有意义,到底该怎样呢?局部性原理在揭开我的设计方案前,我们先来过一下CPU访问存储器时所遵守的局部性原理.在计算机存储介质这个金字塔中,越靠近金字塔顶端,空间越小,但是读取数据越快;越靠近金字塔底端,空间越大,但访问速度也越慢.正式因为这样,所以每次自下而上的数据数据流大小逐层递增, 交换频率逐层递减,如何在时间与空间上取到平衡点是关键.于是有了空间局部性原理和时间局部性原理,力求让计算机的数据流动更高效.空间局部性如果一条数据被访问,那么与它临近的数据也可能要被用到. 比如数组,你访问了索引1上的数据,那么1附近的数据当然很有可能被访问,所以这个时候干脆把1附近的数据也往上加载一个层级.时间局部性如果一条数据项正在被访问,那么在近期它很可能还会被再次访问,所以这个时候干脆就把它留在当前层级,先不急着回收掉.而网站的数据的更新也是具有时间局部性的,像我这样并冷门的网站,基本没人访问,但是一旦访问了,立即就要进行点击量的更新,站点响应速度的记录,没准又会有评论留言,然后要通知管理员进行留言审核.这大概就是不鸣则已,一鸣惊人,一次访问短期内往往立即触发一连串的数据更新,我认为这也是一种时间局部性.所以,在数据同步上,我设计了如下方案. 另起一个线程作为定时任务,主要负责定时数据同步 正常情况下,每小时与Github进行数据同步. 一旦网站数据被更新,检查剩余同步时间是否大于30秒.** 如果大于三十秒,强行把计时器剩余时间设置为30秒.** 如果小于三十秒,不做操作. 计时器时间走完,立即同步数据到Github. 定时沙漏⏳原本文章说到这里就可以结束了,但程序员注定爱代码爱过文字,又恰好我天生爱造轮子,我从令牌桶得到灵感设计了一个乞丐版沙漏计时器,可以用于任何定时任务的执行,班门弄斧,欢迎提出改进意见.Show timepublic class BlogsTimer { private static Stack<int> _upFunnel; //沙漏上部分 private static Stack<int> _downFunnel; //沙漏下部分 private static readonly List<Action> TimerEvents; //定时执行的事件 private static bool _timerSwitch; //沙漏开关 private static readonly int Speed; //每秒消费令牌数量 private static Thread _timerThread; private static readonly object TimerLock; static BlogsTimer() { _upFunnel = new Stack<int>(); _downFunnel = new Stack<int>(); Speed = 1 * 1000; TimerEvents = new List<Action>(); TimerLock = new object(); } //计时器开始 public static void Start(TimeSpan timeSpan) { lock (TimerLock) { _upFunnel.Clear(); _downFunnel.Clear(); for (var i = 0; i < timeSpan.TotalSeconds; i++) { _upFunnel.Push(i); } } _timerSwitch = true; _timerThread = new Thread(Consume); //起一个线程消费桶里的令牌 _timerThread.Start(); LunchEvents(); // 触发事件 } public static void Stop() { _timerSwitch = false; } //给沙漏注册定时执行事件 public static void Register(Action timeEvent) { TimerEvents.Add(timeEvent); timeEvent.Invoke(); } //把沙漏加速到指定的时间 public static void AccelerateTo(TimeSpan timeSpan) { var accelerateSeconds = timeSpan.TotalSeconds; lock (TimerLock) { if (_upFunnel.Count < accelerateSeconds) //当前沙漏中剩余令牌小于设置中秒数,则返回不加速 return; while (_upFunnel.Count > accelerateSeconds && _upFunnel.Count > 1) //令牌数大于秒数,则释放出多余令牌 { _downFunnel.Push(_upFunnel.Pop()); } } } private static void LunchEvents() { TimerEvents.ForEach(a => a.Invoke()); } private static void Consume() { while (_timerSwitch) { lock (TimerLock) { if (_upFunnel.TryPop(out var item)) { _downFunnel.Push(item); } else { LunchEvents(); var tempStack = _downFunnel; //旋转沙漏 _downFunnel = _upFunnel; _upFunnel = tempStack; } } Thread.Sleep(Speed); } } } 源码地址: https://github.com/liuzhenyulive/iBlogs/blob/master/Src/iBlogs.Site.Core/Common/iBlogsTimer.cs演示地址: https://www.iblogs.site
-
不一样的角度一窥多线程 不一样的角度一窥多线程最近在性能调试时,发现了一个有趣的现象,我把代码简化后如下. class Program { static void Main(string[] args) { Console.WriteLine("Start..."); DoSomething(); Console.WriteLine("Ending..."); Console.ReadLine(); } static void DoSomething() { var sum=""; for (int i = 2; i < int.MaxValue; i++) { sum += "s"; } Console.WriteLine(sum.Length); } } 可以看到,非常简单的一段代码,当我用Windows的性能监测工具来监测每个处理器的使用率时,发现了一个有趣的现象.我电脑是四核的I7处理器,执行以上代码后,却只有处理器2一直处理一个比较高的占用率,而其他的三个则处于一个"摸鱼混日子"的状态,处理器1则更过分,你是睡着了吗?同一台电脑上的处理器,难道大家不是有福同享,有难同当的吗? 为什么其他几个处理器就忍心看着处理器2水深火热呢?然后,我就和这个问题死磕上了,恶补了一些操作系统与多线程的知识,现在把一写知识点串起来,分享给大家.分级保护域电脑操作系统提供不同的资源访问级别。在计算机体系结构中,Rings是由两个或更多的特权态组成。在一些硬件或者微代码级别上提供不同特权态模式的CPU架构上,保护环通常都是硬件强制的。Rings是从最高特权级(通常被叫作0级)到最低特权级(通常对应最大的数字)排列的。在大多数操作系统中,Ring 0拥有最高特权,并且可以和最多的硬件直接交互(比如CPU,内存)。在Windows中, User Space,也就是我们自己安装的那些应用程序处理Ring 3,而系统内核就在Ring 0.对于这个问题,举个例子,大家就好理解了.钱不是万能的,但没钱是万万不能的,所以钱是一个家庭的重中之重,家里老婆呢为了这个家的长治久安,掌握家里的财政大权,把家里的小金库守得死死的,但这就意味着我没钱花了吗?当然不是,和老婆大人用正当理由申请不就完事了?😂申请通过之后,老婆大人是允许我直接伸手去家里小金库拿钱吗? 那当然不是,如果我一抓一大把就危险了,所以还得经过她的手从小金库拿钱给我.这个现象,我觉得也是一种分级保护域,所以呢,也一直对老婆大人的这种万恶行径表示理解.操作系统也是这样,CPU,内存这些硬件是电脑安全的根本,所以不能给第三方软件操作权限,想操作硬件,就通过由Ring 0中内核(Kernel)暴露的严格Api进行.用户级线程与内核级线程线程主要有以下两种实现方式- 用户级线程 -用户托管线程。 内核级线程 -作用在内核(操作系统核心)上的操作系统管理的线程。 在上图中,User Space就可以理解为我上个章节中的Ring 3,而Kernel Space就是Ring 0, 在Ring 0中,是可以直接操作CPU,内存等硬件的,而Ring 3不行.以下是用户级线程与内核级线程的对比. 用户级线程 内核级线程 用户线程由用户实现。 内核线程由OS实现。 操作系统无法识别用户级线程。 内核线程被操作系统识别。 用户线程的实现很容易。 内核线程的实现很复杂。 上下文切换时间更少。 上下文切换时间更长。 上下文切换不需要硬件支持。 需要硬件支持。 如果一个用户级别的线程执行阻止操作,则整个过程将被阻止。 如果一个内核线程执行阻止操作,则另一线程可以继续执行。 无法直接发挥多核处理器的优势 可以享受多处理起带来的好处 其中,非常重要的一点,用户级线程无法直接发挥多核处理器的优势,难道我们编写出来的代码只能在一个处理器上运行了吗?这就要讲讲用户级线程模型.用户级线程模型通常,内核级线程可以使用三个模型之一来执行用户级线程。 Many-to-one One-to-one Many-to-many 所有模型都将用户级线程映射到内核级线程,一个内核线程就像一个处理器,它是系统编排任务的基本单位。Many-to-one多对一模型将许多用户级线程映射到一个内核级线程。线程管理是通过线程库在用户空间中完成的。当线程进行阻塞的系统调用时,整个过程将被阻塞。一次只能有一个线程访问内核,因此多个线程无法在多处理器上并行运行。如果用户级线程库是以操作系统不支持的方式实现的,则内核线程将使用多对一关系模型。内核对用户级线程不可见,在它眼里只有内核线程,而在内核线程的眼里,一个进程无非就是一个偶尔被被它翻牌的黑盒子,进程负责用户线程的调度与执行.One-to-one在这种模型下用户级线程与内核级线程之间存在一对一的关系。该模型比多对一模型并发性好,当一个线程进行阻塞系统调用时,它还允许另一个线程运行,所以它支持多个线程以在处理器上并行执行。该模型的缺点是创建用户线程需要相应的内核线程,而创建内核线程开销是很大的.Many-to-many在多对多模型中,m个内核线程处理n个用户线程,其中m < n. 该模型并发性最好,并且不用创建过多的内核线程,涉及到的线程切换同步的开销也更小.真相浮出水面.Net的代码作为托管代码在“托管线程”上执行,而托管线程是在CLR虚拟机上执行的虚拟线程,也是属于用户级线程.正如JIT编译器将“虚拟” IL指令映射到在物理计算机上执行的本机指令一样,CLR的线程基础结构也将“虚拟”托管线程映射到操作系统提供的内核线程。说到这里,我们也差不多有了前面我说的那个现象的答案了,并非其他处理器不想与那个水深火热的处理器有难同享,而是我没有使用多线程,所以执行的程序只有一个主线程,也就是说用户线程数为1.只能是one to one 模型,所以只有一个处理器能参与工作.既然知道了里面的原理,那我们就对前文中的程序进行改造,创建四个线程来执行任务,会不会所有处理器都忙起来呢? class Program { static void Main(string[] args) { Console.WriteLine("Start..."); for (var i = 0; i < 4; i++) { var td=new Thread(DoSomething); td.Start(); } Console.WriteLine("Ending..."); Console.ReadLine(); } static void DoSomething() { var sum=""; for (int i = 2; i < int.MaxValue; i++) { sum += "s"; } Console.WriteLine(sum.Length); } } 可以看到,这次大家的步伐都做到了惊人的一致,四个处理器都被调用起来,加上主线程,这里至少有五个用户线程,所以这里应该是many to many的模型了.谢谢观赏!参考资料:https://en.wikipedia.org/wiki/Protection_ringhttps://stackoverflow.com/questions/15093510/whats-c-sharp-threading-typehttps://github.com/dotnet/coreclr/blob/master/Documentation/botr/threading.md#clr-threading-overview
-
一包辣条钱打造物联网开关 一包辣条钱打造物联网开关为什么想到这个标题呢? 因为我此刻正在吃辣条… 大家应该每天面对的是枯燥的代码,而今天给大家带来一个不一样的东西,有血有肉有生命.背景📊一花一世界,一树一菩提.在我们程序员的眼里, 一花一树, 大概是一台耐操的电脑加上一台丝滑的显示器, 如果两台显示器,那就是人生巅峰. 咳咳, 不错的,我的世界可以没有女朋友, 但是不能没有电脑,不能与它一起睡觉,我也要把它们摆在我的卧室,占为己有.心理上得到了满足,可是我生理上却饱受折磨.每到了我睡觉的时候,显示器上得电源灯,音响得电源灯,路由器的状态灯, 更要命的是,我这台年久的音响,到了晚上,不知道是不是WIFI信号对它有干扰,中觉得它在发出嘟嘟嘟的电流声~~~我当然可以在睡觉前把总开关关闭,早上起来打开电脑再把开关打开,可是咱们是程序员,这种重复的事情就应该交给程序来做!! 🐶然后我想到的是米家的智能插座, 配合其他传感器,可以实现各种场景的自动控制. 可偏偏找不到这样的解决方案:电脑开机-> 电源接通电脑关机-> 电源关闭找不到现成的解决方案,那我就只能自己做一套了,我在网上找到最廉价的物联网开关ESP8266+物联网继电器 ,一套不是998更不是99,而是9.9.为了避免广告嫌疑,我就不放链接了,大家自行某宝搜索🔍.买来之后我的心里也是犯嘀咕的,我一个C#开发,能玩转这种单片机🤪? 然鹅… 我就用一个晚上的时间,真还就被我搞出来了,所以我觉得在座的各位大佬更是没问题.ESP8266 科普(硬件准备)📶ESP8266 是一款国产成本极低且具有完整TCP/IP协议栈的Wi-Fi 物联网控制芯片, 并且深受西方创客的喜爱,生态比较丰富,某宝售价6元左右.与其配套的是这么一个物联网继电器,某宝售价3-4元,把ESP8266插入对应的插孔两即可完美❤结合❤.为了给ESP8266注入生命力,还需要购买这么一个ESP8266的烧录器,某宝8元.软件准备💽 Arduino IDE并安装好esp8266扩展 Arduino IDE下载地址ESP8266扩展包安装方法 下载并安装blinker APP 我需要解释一下,为什么安装这个APP呢? blinker是一家做物联网解决方案的,作为爱好者的我们可以免费接入他们的平台,接入该平台后,我们不管是不是在家,都可以通过手机App控制,并可借助他们的SDK实现小爱同学的语音控制.Android下载点击下载或 在android应用商店搜索“blinker”下载安装IOS下载点击下载或 在app store中搜索“blinker”下载 下载并安装blinker Arduino库 点击下载**Windows:**将下载好的blinker库解压到 我的电脑>文档>Arduino>libraries 文件夹中**Mac OS:**将下载好的blinker库解压到 文稿>Arduino>libraries 文件夹中解压之后目录结构像这样子.获取Secret Key🔑 进入App,点击右上角的“+”号,然后选择 添加设备 点击选择Arduino > WiFi接入 选择要接入的服务商 复制申请到的Secret Key DIY界面🎨 在设备列表页,点击设备图标,进入设备控制面板 按如下图添加button_on和button_off两个按钮 编译并上传示例程序📃在我的GitHub下载为大家准备好的代码https://github.com/liuzhenyulive/ESP8266SmartSwitch(记得Star噢)双击blinker_app_xiaoai.ino用Arduino IDE打开, 输入刚刚在App中申请的Secret Key和你们家的WIFI名称和密码,建议2.4Gwifi, 5Gwifi我没有测试, 还有UDP的监听端口.char auth[] = "2cf492755d68"; //设备key char ssid[] = "2.4"; //路由器wifi ssid char pswd[] = "12345678"; //路由器wifi 密码 unsigned int localUdpPort = 4210; // 局域网中的UDP监听端口 编译并上传程序到esp8266开发板,如果提示缺少什么库,就在Arduino的项目->加载库->管理库 中下载缺失的库即可.当看到如下提示,代表上传成功了.此时不要把它从你的电脑上拔掉,登录你们家的路由器,查看该设置的IP地址.打开在我GitHub仓库中为大家准备的UDP调试工具和串口调试工具,在UDP调试工具中输入该设备的IP和UDP监听端口,发送on,串口调试工具能接收到on,发送off能接收到off.同时,我们打开点灯blinker的app,如果你幸运的话它应该已经上线了,在app中点击on或off, 串口调试工具有对应的响应输出.通电⚡最后也是最🤑躁动人心🤑的一步,给继电器接上5V的供电,拿一根没用的USB线剪开,一般红线是正极,负极请自行尝试,然后把你要控制的设备的火线(红色)断电 断电 断电 后剪断,分别接入负载入与负载出.通电成功后,设备大概是这样子.UDP控制📧我用我的老本行.net core给大家写了一个命令行工具 通过如下命令调用该工具,即可实现该设备的开和关.CSharpUdpClient.exe 192.168.1.5 4210 on CSharpUdpClient.exe 192.168.1.5 4210 off APP控制📱App的控制,打开电灯blinker app, 该设备在线后,可通过设备内你自定义的两个图标控制该设备的开关. 小爱同学📢小爱同学的控制就有点复杂了,首先要下载米家app, 在我的 -> 其他平台设备->绑定点灯科技的账号并同步设备.然后下载小爱同学app, 用小米账户登录,添加训练,比如打开电脑,关闭电脑,即可语音控制开关.电脑开关机控制💻Win+R 输入 gpedit.msc 在电脑配置->电脑设置-> 开关机脚本内,添加我在前面UDP控制的那一章节中描述的脚本,即可在电脑开机时自动打开显示器,音响等设备, 晚上睡觉前,电脑关机的时候,也会自动把电源断开.同理,你也可以新建两个bat文件,在文件里面把命令写入,在我的GitHub中已经把相关文件准备好了,仅供参考.所有代码和工具可以去我的GitHub仓库下载,好了,今晚总算睡个好觉了(~﹃~)~zZ 能得到心理和生理得满足,我真是个幸福的人😈.https://github.com/liuzhenyulive/ESP8266SmartSwitch
-
你对幻读可能存在误解 前言每次谈到数据库的事务隔离级别,大家一定会看到这张表.其中,可重复读这个隔离级别,有效地防止了脏读和不可重复读,但仍然可能发生幻读,可能发生幻读就表示可重复读这个隔离级别防不住幻读吗?我不管从数据库方面的教科书还是一些网络教程上,经常看到RR级别是可以重复读的,但是无法解决幻读,只有可串行化(Serializable)才能解决幻读,这个说法是否正确呢?在这篇文章中,我将重点围绕MySQL中可重复读(Repeatable read)能防住幻读吗?这一问题展开讨论,相信看完这篇文章后,你一定会对事务隔离级别有新的认识.我们的数据库中有如下结构和数据的Users表,下文中我们将对这张表进行操作,长文预警,读完此篇文章,大概需要您二十至三十分钟.什么是幻读?在说幻读之前,我们要先来了解脏读和不可重复读.脏读当一个事务读取到另外一个事务修改但未提交的数据时,就可能发生脏读。在我们的例子中,事务2修改了一行,但是没有提交,事务1读了这个没有提交的数据。现在如果事务2回滚了刚才的修改或者做了另外的修改的话,事务1中查到的数据就是不正确的了,所以这条数据就是脏读。不可重复读“不可重复读”现象发生在当执行SELECT 操作时没有获得读锁或者SELECT操作执行完后马上释放了读锁; 另外一个事务对数据进行了更新,读到了不同的结果.在这个例子中,事务2提交成功,因此他对id为1的行的修改就对其他事务可见了。导致了事务1在此前读的age=1,第二次读的age=2,两次结果不一致,这就是不可重复读.幻读“幻读”又叫"幻象读",是’‘不可重复读’‘的一种特殊场景:当事务1两次执行’‘SELECT … WHERE’'检索一定范围内数据的操作中间,事务2在这个表中创建了(如[[INSERT]])了一行新数据,这条新数据正好满足事务1的“WHERE”子句。如图事务1执行了两遍同样的查询语句,第二遍比第一遍多出了一条数据,这就是幻读。三者到底什么区别三者的场景介绍完,但是一定仍然有很多同学搞不清楚,它们到底有什么区别,我总结一下.脏读:指读到了其他事务未提交的数据.不可重复读: 读到了其他事务已提交的数据(update).不可重复读与幻读都是读到其他事务已提交的数据,但是它们针对点不同.不可重复读:update.幻读:delete,insert.MySQL中的四种事务隔离级别未提交读未提交读(READ UNCOMMITTED)是最低的隔离级别,在这种隔离级别下,如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据.把脏读的图拿来分析分析,因为事务2更新id=1的数据后,仍然允许事务1读取该条数据,所以事务1第二次执行查询,读到了事务2更新的结果,产生了脏读.已提交读由于MySQL的InnoDB默认是使用的RR级别,所以我们先要将该session开启成RC级别,并且设置binlog的模式SET session transaction isolation level read committed; SET SESSION binlog_format = 'ROW';(或者是MIXED) 在已提交读(READ COMMITTED)级别中,读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行,会对该写锁一直保持直到到事务提交.同样,我们来分析脏读,事务2更新id=1的数据后,在提交前,会对该对象写锁,所以事务1读取id=1的数据时,会一直等待事务2结束,处于阻塞状态,避免了产生脏读.同样,来分析不可重复读,事务1读取id=1的数据后并没有锁住该数据,所以事务2能对这条数据进行更新,事务2对更新并提交后,该数据立即生效,所以事务1再次执行同样的查询,查询到的结果便与第一次查到的不同,所以已提交读防不了不可重复读.可重复度在可重复读(REPEATABLE READS)是介于已提交读和可串行化之间的一种隔离级别(废话😅),它是InnoDb的默认隔离级别,它是我这篇文章的重点讨论对象,所以在这里我先卖个关子,后面我会详细介绍.可串行化可串行化(Serializable )是高的隔离级别,它求在选定对象上的读锁和写锁保持直到事务结束后才能释放,所以能防住上诉所有问题,但因为是串行化的,所以效率较低.了解到了上诉的一些背景知识后,下面正式开始我们的议题.可重复读(Repeatable read)能防住幻读吗?可重复读在讲可重复读之前,我们先在mysql的InnoDB下做下面的实验.可以看到,事务A既没有读到事务B更新的数据,也没有读到事务C添加的数据,所以在这个场景下,它既防住了不可重复读,也防住了幻读.到此为止,相信大家已经知道答案了,这是怎么做到的呢?悲观锁与乐观锁我们前面说的在对象上加锁,是一种悲观锁机制,有很多文章说可重复读的隔离级别防不了幻读, 是认为可重复读会对读的行加锁,导致他事务修改不了这条数据,直到事务结束,但是这种方案只能锁住数据行,如果有新的数据进来,是阻止不了的,所以会产生幻读.可是MySQL、ORACLE、PostgreSQL等已经是非常成熟的数据库了,怎么会单纯地采用这种如此影响性能的方案呢?我来介绍一下悲观锁和乐观锁.悲观锁正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。读取数据时给加锁,其它事务无法修改这些数据。修改删除数据时也要加锁,其它事务无法读取这些数据。乐观锁相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。MySQL、ORACLE、PostgreSQL等都是使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免不可重复读和幻读,MVCC的实现没有固定的规范,每个数据库都会有不同的实现方式,这里讨论的是InnoDB的MVCC。MVCC(多版本并发控制)在InnoDB中,会在每行数据后添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。 在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。 在可重读Repeatable reads事务隔离级别下: SELECT时,读取创建版本号<=当前事务版本号,删除版本号为空或>当前事务版本号。 INSERT时,保存当前事务版本号为行的创建版本号 DELETE时,保存当前事务版本号为行的删除版本号 UPDATE时,插入一条新纪录,保存当前事务版本号为行创建版本号,同时保存当前事务版本号到原来删除的行 通过MVCC,虽然每行记录都要额外的存储空间来记录version,需要更多的行检查工作以及一些额外的维护工作,但可以减少锁的使用,大多读操作都不用加锁,读取数据操作简单,性能好.细心的同学应该也看到了,通过MVCC读取出来的数据其实是历史数据,而不是最新数据,这在一些对于数据时效特别敏感的业务中,很可能出问题,这也是MVCC的短板之处,有办法解决吗? 当然有.MCVV这种读取历史数据的方式称为快照读(snapshot read),而读取数据库当前版本数据的方式,叫当前读(current read).快照读我们平时只用使用select就是快照读,这样可以减少加锁所带来的开销.select * from table .... 当前读对于会对数据修改的操作(update、insert、delete)都是采用当前读的模式。在执行这几个操作时会读取最新的记录,即使是别的事务提交的数据也可以查询到。假设要update一条记录,但是在另一个事务中已经delete掉这条数据并且commit了,如果update就会产生冲突,所以在update的时候需要知道最新的数据。读取的是最新的数据,需要加锁。以下第一个语句需要加共享锁,其它都需要加排它锁。select * from table where ? lock in share mode; select * from table where ? for update; insert; update; delete; 我们再利用当前读来做试验.可以看到在读提交的隔离级别中,事务1修改了所有class_id=1的数据,当时当事务2 insert后,事务A莫名奇妙地多了一行class_id=1的数据,而且没有被之前的update所修改,产生了读提交下的的幻读.而在可重复度的隔离级别下,情况就完全不同了.事务1在update后,对该数据加锁,事务B无法插入新的数据,这样事务A在update前后数据保持一致,避免了幻读,可以明确的是,update锁的肯定不只是已查询到的几条数据,因为这样无法阻止insert,有同学会说,那就是锁住了整张表呗.还是那句话, Mysql已经是个成熟的数据库了,怎么会采用如此低效的方法呢? 其实这里的锁,是通过next-key锁实现的.Next-Key锁在Users这张表里面,class_id是个非聚簇索引,数据库会通过B+树维护一个非聚簇索引与主键的关系,简单来说,我们先通过class_id=1找到这个索引所对应所有节点,这些节点存储着对应数据的主键信息,即id=1,我们再通过主键id=1找到我们要的数据,这个过程称为回表.不懂数据库索引的底层原理?那是因为你心里没点b树前往学习: https://www.cnblogs.com/sujing/p/11110292.html我本想用我们文章中的例子来画一个B+树,可是画得太丑了,为了避免拉低此偏文章B格.所以我想引用上面那边文章中作者画的B+树来解释Next-key.假设我们上面用到的User表需要对Name建立非聚簇索引,是怎么实现的呢?我们看下图:B+树的特点是所有数据都存储在叶子节点上,以非聚簇索引的秦寿生为例,在秦寿生的右叶子节点存储着所有秦寿生对应的Id,即图中的34,在我们对这条数据做了当前读后,就会对这条数据加行锁,对于行锁很好理解,能够防止其他事务对其进行update或delete,但为什么要加GAP锁呢?还是那句话,B+树的所有数据存储在叶子节点上,当有一个新的叫秦寿生的数据进来,一定是排在在这条id=34的数据前面或者后面的,我们如果对前后这个范围进行加锁了,那当然新的秦寿生就插不进来了.那如果有一个新的范统要插进行呢? 因为范统的前后并没有被锁住,是能成功插入的,这样就极大地提高了数据库的并发能力.马失前蹄上文中说了可重复读能防不可重复读,还能防幻读,它能防住所有的幻读吗?当然不是,也有马失前蹄的时候.比如如下的例子:1.a事务先select,b事务insert确实会加一个gap锁,但是如果b事务commit,这个gap锁就会释放(释放后a事务可以随意操作),2.a事务再select出来的结果在MVCC下还和第一次select一样,3.接着a事务不加条件地update,这个update会作用在所有行上(包括b事务新加的),4.a事务再次select就会出现b事务中的新行,并且这个新行已经被update修改了.Mysql官方给出的幻读解释是:只要在一个事务中,第二次select多出了row就算幻读, 所以这个场景下,算出现幻读了.那么文章最后留个问题,你知道为什么上诉例子会出现幻读吗?欢迎留言讨论.参考文章:MySQL 5.6 Reference Manualunderstanding InnoDB transaction isolation levelsMySQL · 源码分析 · InnoDB Repeatable Read隔离级别之大不同不懂数据库索引的底层原理?那是因为你心里没点b树Innodb中的事务隔离级别和锁的关系MySQL InnoDB中的行锁 Next-Key Lock消除幻读
-
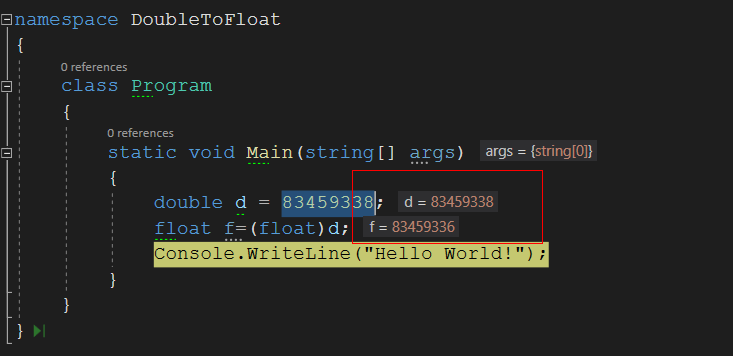
分析一次double强转float的翻车原因 背景人逢喜事精神爽,总算熬到下班撩~~正准备和同事打个招呼回家,被同事拖住问了.🙋♂️: 你们组做的那块代码,把double类型数据成float有问题啊💨.💁♀️: 嗯?不对是正常啊,float精度是没有double高,但float能保存到小数点后好多位,对我们来说完全够用了!🙋♂️: 不是啊,这不是小数点多少位的问题,而是现在整型数据,转出来也有问题啊,你看.💁♀️: XX00😱… 这什么鬼?看到这个结果,差点闪到我的老腰🤦,咋不按套路出牌呢?然后,下班路上,感觉我好像被我挚爱的.Net欺骗了💔,double强转float用了这么多年,咋说不对就不对了?.Net不靠谱啊!浮点类型数据的存储当然,我内心还是相信.Net是清白的,所以刨根究底,网上找的资料大多是说这种强转会照成小数点后的精度的问题,可是造成整数位的问题精度问题却少有人提及.为了理解这个问题,我们要从一些大学计算机基础的相关知识讲起😂.float和double有什么不同? float四个字节,double八个字节. float范围从10-38到1038 和 -1038到-10-38, double的范围从10-308到10308 和 -10-308到-10-308 当然了,这都是废话🤷, 重点是下面这条. float是单精度浮点数,double是双精度浮点数. 单精度与双精度什么区别根据国际标准IEEE 754,任意一个二进制浮点数V可以表示成下面的形式: (-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。 M表示有效数字,大于等于1,小于2。 2^E表示指数位。 举例来说,十进制的5.0,写成二进制是101.0,相当于1.01×2^2。那么,按照上面V的格式,可以得出s=0,M=1.01,E=2。十进制的-5.0,写成二进制是-101.0,相当于-1.01×2^2。那么,s=1,M=1.01,E=2。对于32位的单精度浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。对于64位的双精度浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。经过上面关于浮点数的介绍,相信你可能还是一头雾水,就像下面这幅漫画展示的那样🐎.浮点数转成内存存储为了避免产生上面那种画马的跳跃,我们一小步一小步,看看浮点数据具体怎么在内存中存储的.双精度与单精度类似,这里我以单精度为例. 先将这个实数的绝对值化为二进制格式。 将这个二进制格式实数的小数点左移或右移n位,直到小数点移动到第一个有效数字的右边。 从小数点右边第一位开始数出二十三位数字放入第22到第0位。 如果实数是正的,则在第31位放入“0”,否则放入“1”。 ⭐如果n 是左移得到的,说明指数是正的,第30位放入“1”。如果n是右移得到的或n=0,则第30位放入“0”。 如果n是左移得到的,则将n减去1后化为二进制,并在左边加“0”补足七位,放入第29到第23位。如果n是右移得到的或n=0,则将n化为二进制后在左边加“0”补足七位,再各位求反,再放入第29到第23位。 我们先用上述步骤尝试把9.0转化成二进制存储形式.我们可以通过这个地址校验计算结果的正确性. https://www.h-schmidt.net/FloatConverter/IEEE754.html可以看到,与我们的计算结果完全一致.翻车分析现在我们用上面的步骤,把照成翻车的83459338转成内存存储形式看看.通过在线工具转换后证实我们的转换完全正确.然后我们再把数据转回来.S是第31位,为0, E =0011001(25)+1=26, 重点在M,它是1.(有效数字位)即 1.001111100101111101000011.00111110010111110100001乘上2的26次方,为100111110010111110100001000,将其转换为十进制,为 83459336没错,就是83459336,而不是83459338🌋83459338=> 10011111001011111010000101083459336=> 100111110010111110100001000可以看到,两个数字转成成二进制后,倒数第二位产生了差异,而产生这种的差异的原因就是单精度浮点数小数位23位不足以存储所有二进制数(26位).🚑这场事故告诉我们,强转虽好,容易翻车.
-
聊一聊数据库中的锁 背景数据库中有一张叫后宫佳丽的表,每天都有几百万新的小姐姐插到表中,光阴荏苒,夜以继日,日久生情,时间长了,表中就有了几十亿的小姐姐数据,看到几十亿的小姐姐,每到晚上,我可愁死了,这么多小姐姐,我翻张牌呢?办法当然是精兵简政,删除那些age>18的,给年轻的小姐姐们留位置…于是我在数据库中添加了一个定时执行的小程序,每到周日,就自动运行如下的脚本delete from `后宫佳丽` where age>18 一开始还自我感觉良好,后面我就发现不对了,每到周日,这个脚本一执行就是一整天,运行的时间有点长是小事,重点是这大好周日,我再想读这张表的数据,怎么也读不出来了,怎是一句空虚了得,我好难啊!为什么编不下去了,真实背景是公司中遇到的一张有海量数据表,每次一旦执行历史数据的清理,我们的程序就因为读不到这张表的数据,疯狂地报错,后面一查了解到,原来是因为定时删除的语句设计不合理,导致数据库中数据由行锁(Row lock)升级为表锁(Table lock)了😂.解决这个问题的过程中把数据库锁相关的学习了一下,这里把学习成果,分享给大家,希望对大家有所帮助.我将讨论SQL Server锁机制以及如何使用SQL Server标准动态管理视图监视SQL Server 中的锁,相信其他数据的锁也大同小异,具有一定参考意义.铺垫知识在我开始解释SQL Server锁定体系结构之前,让我们花点时间来描述ACID(原子性,一致性,隔离性和持久性)是什么。ACID是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。ACID原子性(Atomicity)一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。一致性(Consistency)在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。隔离性(Isolation)数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。持久性(Durability)事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。来源:维基百科 https://zh.wikipedia.org/wiki/ACID事务 (Transaction:)事务是进程中最小的堆栈,不能分成更小的部分。此外,某些事务处理组可以按顺序执行,但正如我们在原子性原则中所解释的那样,即使其中一个事务失败,所有事务块也将失败。锁定 (Lock)锁定是一种确保数据一致性的机制。SQL Server在事务启动时锁定对象。事务完成后,SQL Server将释放锁定的对象。可以根据SQL Server进程类型和隔离级别更改此锁定模式。这些锁定模式是:锁定层次结构SQL Server具有锁定层次结构,用于获取此层次结构中的锁定对象。数据库位于层次结构的顶部,行位于底部。下图说明了SQL Server的锁层次结构。共享(S)锁 (Shared (S) Locks)当需要读取对象时,会发生此锁定类型。这种锁定类型不会造成太大问题。独占(X)锁定 (Exclusive (X) Locks)发生此锁定类型时,会发生以防止其他事务修改或访问锁定对象。更新(U)锁 (Update (U) Locks)此锁类型与独占锁类似,但它有一些差异。我们可以将更新操作划分为不同的阶段:读取阶段和写入阶段。在读取阶段,SQL Server不希望其他事务有权访问此对象以进行更改,因此,SQL Server使用更新锁。意图锁定 (Intent Locks)当SQL Server想要在锁定层次结构中较低的某些资源上获取共享(S)锁定或独占(X)锁定时,会发生意图锁定。实际上,当SQL Server获取页面或行上的锁时,表中需要设置意图锁。SQL Server locking了解了这些背景知识后,我们尝试再SQL Server找到这些锁。SQL Server提供了许多动态管理视图来访问指标。要识别SQL Server锁,我们可以使用sys.dm_tran_locks视图。在此视图中,我们可以找到有关当前活动锁管理的大量信息。在第一个示例中,我们将创建一个不包含任何索引的演示表,并尝试更新此演示表。CREATE TABLE TestBlock (Id INT , Nm VARCHAR(100)) INSERT INTO TestBlock values(1,'CodingSight') In this step, we will create an open transaction and analyze the locked resources. BEGIN TRAN UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1 select @@SPID 再获取到了SPID后,我们来看看sys.dm_tran_lock视图里有什么。select * from sys.dm_tran_locks WHERE request_session_id=74 此视图返回有关活动锁资源的大量信息,但是是一些我们难以理解的一些数据。因此,我们必须将sys.dm_tran_locks join 一些其他表。SELECT dm_tran_locks.request_session_id, dm_tran_locks.resource_database_id, DB_NAME(dm_tran_locks.resource_database_id) AS dbname, CASE WHEN resource_type = 'OBJECT' THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id) ELSE OBJECT_NAME(partitions.OBJECT_ID) END AS ObjectName, partitions.index_id, indexes.name AS index_name, dm_tran_locks.resource_type, dm_tran_locks.resource_description, dm_tran_locks.resource_associated_entity_id, dm_tran_locks.request_mode, dm_tran_locks.request_status FROM sys.dm_tran_locks LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id WHERE resource_associated_entity_id > 0 AND resource_database_id = DB_ID() and request_session_id=74 ORDER BY request_session_id, resource_associated_entity_id 在上图中,您可以看到锁定的资源。SQL Server获取该行中的独占锁。(RID:用于锁定堆中单个行的行标识符)同时,SQL Server获取页中的独占锁和TestBlock表意向锁。这意味着在SQL Server释放锁之前,任何其他进程都无法读取此资源,这是SQL Server中的基本锁定机制。现在,我们将在测试表上填充一些合成数据。TRUNCATE TABLE TestBlock DECLARE @K AS INT=0 WHILE @K <8000 BEGIN INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' ) SET @K=@K+1 END --After completing this step, we will run two queries and check the sys.dm_tran_locks view. BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<5000 在上面的查询中,SQL Server获取每一行的独占锁。现在,我们将运行另一个查询。BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<7000 在上面的查询中,SQL Server在表上创建了独占锁,因为SQL Server尝试为这些将要更新的行获取大量RID锁,这种情况会导致数据库引擎中的大量资源消耗,因此,SQL Server会自动将此独占锁定移动到锁定层次结构中的上级对象(Table)。我们将此机制定义为Lock Escalation, 这就是我开篇所说的锁升级,它由行锁升级成了表锁。根据官方文档的描述存在以下任一条件,则会触发锁定升级: 单个Transact-SQL语句在单个非分区表或索引上获取至少5,000个锁。 单个Transact-SQL语句在分区表的单个分区上获取至少5,000个锁,并且ALTER TABLE SET LOCK_ESCALATION选项设置为AUTO。 数据库引擎实例中的锁数超过了内存或配置阈值。 https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms184286(v=sql.105)如何避免锁升级防止锁升级的最简单,最安全的方法是保持事务的简短,并减少昂贵查询的锁占用空间,以便不超过锁升级阈值,有几种方法可以实现这一目标.将大批量操作分解为几个较小的操作例如,在我开篇所说的在几十亿条数据中删除小姐姐的数据:delete from `后宫佳丽` where age>18 我们可以不要这么心急,一次只删除500个,可以显着减少每个事务累积的锁定数量并防止锁定升级。例如:SET ROWCOUNT 500 delete_more: delete from `后宫佳丽` where age>18 IF @@ROWCOUNT > 0 GOTO delete_more SET ROWCOUNT 0 创建索引使查询尽可能高效来减少查询的锁定占用空间如果没有索引会造成表扫描可能会增加锁定升级的可能性, 更可怕的是,它增加了死锁的可能性,并且通常会对并发性和性能产生负面影响。根据查询条件创建合适的索引,最大化提升索引查找的效率,此优化的一个目标是使索引查找返回尽可能少的行,以最小化查询的的成本。如果其他SPID当前持有不兼容的表锁,则不会发生锁升级锁定升级始总是升级成表锁,而不会升级到页面锁定。如果另一个SPID持有与升级的表锁冲突的IX(intent exclusive)锁定,则它会获取更细粒度的级别(行,key或页面)锁定,定期进行额外的升级尝试。表级别的IX(intent exclusive)锁定不会锁定任何行或页面,但它仍然与升级的S(共享)或X(独占)TAB锁定不兼容。如下所示,如果有个操作始终在不到一小时内完成,您可以创建包含以下代码的sql,并安排在操作的前执行BEGIN TRAN SELECT * FROM mytable (UPDLOCK, HOLDLOCK) WHERE 1=0 WAITFOR DELAY '1:00:00' COMMIT TRAN 此查询在mytable上获取并保持IX锁定一小时,这可防止在此期间对表进行锁定升级。Happy Ending好了,不说了,小姐姐们因为不想离我开又打起来了(死锁).参考文献:SQL Server Transaction Locking and Row Versioning Guide https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-guides/jj856598(v=sql.110)SQL Server, Locks Object https://docs.microsoft.com/en-us/sql/relational-databases/performance-monitor/sql-server-locks-object?view=sql-server-2017How to resolve blocking problems that are caused by lock escalation in SQL Server https://support.microsoft.com/es-ve/help/323630/how-to-resolve-blocking-problems-that-are-caused-by-lock-escalation-inMain concept of SQL Server locking https://codingsight.com/main-concept-of-sql-server-locking/