搜索到
26
篇与
的结果
-
 C# 9.0新特性 CandidateFeaturesForCSharp9看到标题,是不是认为我把标题写错了?是的,C# 8.0还未正式发布,在官网它的最新版本还是Preview 5,通往C#9的漫长道路却已经开始.前写天收到了活跃在C#一线的BASSAM ALUGILI给我分享C# 9.0新特性,我在他文章的基础上进行翻译,希望能对大家有所帮助.这是世界上第一篇关于C#9候选功能的文章。阅读完本文后,你将会为未来可能遇到的C# 9.0新特性做好更充分的准备。这篇文章基于, C# 9.0候选新特性 原生大小的数字类型这次引入一组新类型(nint,nuint,nfloat等)'n’表示native(原生),该特性允许声明一个32位或64位的数据类型,这取决于操作系统的平台类型。nint nativeInt = 55; take 4 bytes when I compile in 32 Bit host. nint nativeInt = 55; take 8 bytes when I compile in 64 Bit host with x64 compilation settings. xamarin中已存在类似的概念, xamarin原生类型 Records and Pattern-based With-Expression这个功能我等待了很长时间,Records是一种轻量级的不可变类型,它可以是方法,属性,运算符等,它允许我们进行结构的比较, 此外,默认情况下,Records属性是只读的。Records可以是值类型或引用类型。Examplepublic class Point3D(double X, double Y, double Z); public class Demo { public void CreatePoint() { var p = new Point3D(1.0, 1.0, 1.0); } } 这些代码会被编译器转化如下形式.public class Point3D { private readonly double <X>k__BackingField; private readonly double <Y>k__BackingField; private readonly double <Z>k__BackingField; public double X {get {return <X>k__BackingField;}} public double Y{get{return <Y>k__BackingField;}} public double Z{get{return <Z>k__BackingField;}} public Point3D(double X, double Y, double Z) { <X>k__BackingField = X; <Y>k__BackingField = Y; <Z>k__BackingField = Z; } public bool Equals(Point3D value) { return X == value.X && Y == value.Y && Z == value.Z; } public override bool Equals(object value) { Point3D value2; return (value2 = (value as Point3D)) != null && Equals(value2); } public override int GetHashCode() { return ((1717635750 * -1521134295 + EqualityComparer<double>.Default.GetHashCode(X)) * -1521134295 + EqualityComparer<double>.Default.GetHashCode(Y)) * -1521134295 + EqualityComparer<double>.Default.GetHashCode(Z); } } Using Records: public class Demo { public void CreatePoint() { Point3D point3D = new Point3D(1.0, 1.0, 1.0); } } Records迎合了基于表达式形式编程的特性,使得我们可以这样使用它.var newPoint3D = Point3D.With(x: 42); 这样我们创建的新Point(new Point3D)就像现有的一个(point3D)一样并把X的值更改为42。这个特性于基于pattern matching也非常有效,我会在我的下一篇文章中介绍这一点.那么我们为什么要使用Records而不是用结构体呢?为了回答这些问题,我引用了了Reddit的一句话:“结构体是你必须要有一些约定来实现的东西。你不必手动地去让它只读,你也不用去实现他们的比较逻辑,但如果你不这样做,那你就失去了使用结构体的意义,编译器不会强制执行这些约束"。Records类型由是编译器实现,这意味着您必须满足所有这些条件并且不能错误, 因此,它们不仅可以减少重复代码,还可以消除一大堆潜在的错误。此外,这个功能在F#中存在了十多年,其他语言如(Scala,Kotlin)也有类似的概念。F#type Greeter(name: string) = member this.SayHi() = printfn "Hi, %s" name Scalaclass Greeter(name: String) { def SayHi() = println("Hi, " + name) } Kotlinclass Greeter(val name: String) { fun sayhi() { println("Hi, ${name}"); } } 在没有Records之前,我们要实现类似的功能,C#代码要这么写C#public class Greeter { private readonly string _name; public Greeter(string name) { _name = name; } public void Greet() { Console.WriteLine($ "Hello, {_name}"); } } 有了Records之后,我们可以将C#代码大大地减少了,ublic class Greeter(name: string) { public void Greet() { Console.WriteLine($ "Hello, {_name}"); } } Less code! = I love it!Type Classes此功能的灵感来自Haskell,它是我最喜欢的功能之一。正如我两年前在我文章中所说,C#将实现更多的函数式编(FP)程概念,Type Classes就是FP概念之一。在函数式编程中,Type Classes允许您在类型上添加一组操作,但不实现它。由于实现是在其他地方完成的,这是一种多态,它比面向对象编程语言中的class更灵活。Type Classes和C#接口具有相似的用途,但它们的工作方式有所不同,在某些情况下,由于处理固定类型而不是继承层次结构,因此Type Classes更易于使用。此这特性最初与“extending everything”功能一起引入,您可以将它们组合在一起,如Mads Torgersen给出的例子所示。我引用了官方提案中的一些结论:“一般来说,”shape“(shape是Type Classes的一个新的关键字)声明非常类似于接口声明,除了以下情况, 它可以定义任何类型的成员(包括静态成员) 可以通过扩展实现 只能在指定的地方当作一种类型使用(作用域)“ Haskell中 Type Classes示例。class Eq a where (==) :: a -> a -> Bool (/=) :: a -> a -> Bool “Eq”是类名,而==,/ =是类中的操作。类型“a”是类“Eq”的实例。如果我们将上述例子用C#接口实现将会是这样.interface Num<A> { A Add(A a, A b); A Mult(A a, A b); A Neg(A a); } struct NumInt : Num<int> { public int Add(int a, int b) => a + b; public int Mult(int a, int b) => a * b; public int Neg(int a) => -a; } 如果我们用Type Classes实现C# 功能会是这样shape Num<A> { A Add(A a, A b); A Mult(A a, A b); A Neg(A a); } instance NumInt : Num<int> { int Add(int a, int b) => a + b; int Mult(int a, int b) => a * b; int Neg(int a) => -a; } 通过上面例子,可以看到接口和shape的语法类似 ,那我们再来看看Mads Torgersen给出的例子Note:shape不是一种类型。相反,shape的主要目的是用作通用约束,限制类型参数以具有正确的形状,同时允许通用声明的主体使用该形状,原始来源public shape SGroup<T> { static T operator +(T t1, T t2); static T Zero {get;} } 这个声明说如果一个类型在T上实现了一个+运算符并且具有0静态属性,那么它可以是一个SGroup 。给int添加静态成员Zeropublic extension IntGroup of int: SGroup<int> { public static int Zero => 0; } 定义一个AddAll方法public static AddAll<T>(T[] ts) where T: SGroup<T> // shape used as constraint { var result = T.Zero; // Making use of the shape's Zero property foreach (var t in ts) { result += t; } // Making use of the shape's + operator return result; } 让我们用一些整数调用AddAll方法,int[] numbers = { 5, 1, 9, 2, 3, 10, 8, 4, 7, 6 }; WriteLine(AddAll(numbers)); // infers T = int 这就是Type class 的妙处,慢慢消化感受一下??Dictionary Literals引入更简单的语法来创建初始化的Dictionary <TKey,TValue>对象,而无需指定Dictionary类型名称或类型参数。使用用于数组类型推断的现有规则推断字典的类型参数。// C# 1..8 var x = new Dictionary <string,int> () { { "foo", 4 }, { "bar", 5 }}; // C# 9 var x = ["foo":4, "bar": 5]; 该特性使C#中的字典工作更简单,并删除冗余代码。此外,值得一提的是,在F#和Swift等其他编程语言中也使用了类似的字典语法。Params Span 允许params语法使用Span 这个帮助来实现没有任何堆分配的params参数传递。此功能可以使params方法的使用更加高效。新的语法如下,void Foo(params Span<int> values); struct允许使用无参构造函数到目前为止,在C#中不允许在结构体声明中使用无参构造函数,在C#9中,将删除此限制。StackOverflow示例public struct Rational { private long numerator; private long denominator; public Rational(long num, long denom) { /* Todo: Find GCD etc. */ } public Rational(long num) { numerator = num; denominator = 1; } public Rational() // This is not allowed { numerator = 0; denominator = 1; } } 链接到StackOverflow示例其实CLR已经允许值类型数据具有无参构造函数,只是C# 对这个功能进行了限制,在C# 9.0中可能会消除这种限制.固定大小的缓冲区这些提供了一种通用且安全的机制,用于向C#语言声明固定大小的缓冲区。目前,用户可以在不安全的环境中创建固定大小的缓冲区。但是,这需要用户处理指针,手动执行边界检查,并且只支持一组有限的类型(bool,byte,char,short,int,long,sbyte,ushort,uint,ulong,float和double)。该特性引入后将使固定大小的缓冲区变得安全安全,如下例所示。可以通过以下方式声明一个安全的固定大小的缓冲区,public fixed DXGI_RGB GammaCurve[1025]; 该声明将由编译器转换为内部表示,类似于以下内容,[FixedBuffer(typeof(DXGI_RGB), 1024)] public ConsoleApp1.<Buffer>e__FixedBuffer_1024<DXGI_RGB> GammaCurve; // Pack = 0 is the default packing and should result in indexable layout. [CompilerGenerated, UnsafeValueType, StructLayout(LayoutKind.Sequential, Pack = 0)] struct <Buffer>e__FixedBuffer_1024<T> { private T _e0; private T _e1; // _e2 ... _e1023 private T _e1024; public ref T this[int index] => ref (uint)index <= 1024u ? ref RefAdd<T>(ref _e0, index): throw new IndexOutOfRange(); } Uft8字符串文字它是关于定义一种新的字符串类型UTF8String,它将是,System.UTF8String myUTF8string ="Test String"; Base(T)此功能用于解决默认接口方法中的覆盖冲突问题:interface I1 { void M(int) { } } interface I2 { void M(short) { } } interface I3 { override void I1.M(int) { } } interface I4 : I3 { void M2() { base(I3).M(0) // Which M should be used here? What does this do? } } 更多信息, https://github.com/dotnet/csharplang/issues/2337 https://github.com/dotnet/csharplang/blob/master/meetings/2019/LDM-2019-02-27.md 摘要您已经阅读了第一个C#9候选特性。正如您所看到的,许多新功能受到其他编程语言或编程范例的启发,而不是自我创新,这些特性大部分在在社区中得到了广泛认可,所以引入C# 后应该也会给大家带来不错的体验.原文 : https://www.c-sharpcorner.com/article/candidate-features-for-c-sharp-9/
C# 9.0新特性 CandidateFeaturesForCSharp9看到标题,是不是认为我把标题写错了?是的,C# 8.0还未正式发布,在官网它的最新版本还是Preview 5,通往C#9的漫长道路却已经开始.前写天收到了活跃在C#一线的BASSAM ALUGILI给我分享C# 9.0新特性,我在他文章的基础上进行翻译,希望能对大家有所帮助.这是世界上第一篇关于C#9候选功能的文章。阅读完本文后,你将会为未来可能遇到的C# 9.0新特性做好更充分的准备。这篇文章基于, C# 9.0候选新特性 原生大小的数字类型这次引入一组新类型(nint,nuint,nfloat等)'n’表示native(原生),该特性允许声明一个32位或64位的数据类型,这取决于操作系统的平台类型。nint nativeInt = 55; take 4 bytes when I compile in 32 Bit host. nint nativeInt = 55; take 8 bytes when I compile in 64 Bit host with x64 compilation settings. xamarin中已存在类似的概念, xamarin原生类型 Records and Pattern-based With-Expression这个功能我等待了很长时间,Records是一种轻量级的不可变类型,它可以是方法,属性,运算符等,它允许我们进行结构的比较, 此外,默认情况下,Records属性是只读的。Records可以是值类型或引用类型。Examplepublic class Point3D(double X, double Y, double Z); public class Demo { public void CreatePoint() { var p = new Point3D(1.0, 1.0, 1.0); } } 这些代码会被编译器转化如下形式.public class Point3D { private readonly double <X>k__BackingField; private readonly double <Y>k__BackingField; private readonly double <Z>k__BackingField; public double X {get {return <X>k__BackingField;}} public double Y{get{return <Y>k__BackingField;}} public double Z{get{return <Z>k__BackingField;}} public Point3D(double X, double Y, double Z) { <X>k__BackingField = X; <Y>k__BackingField = Y; <Z>k__BackingField = Z; } public bool Equals(Point3D value) { return X == value.X && Y == value.Y && Z == value.Z; } public override bool Equals(object value) { Point3D value2; return (value2 = (value as Point3D)) != null && Equals(value2); } public override int GetHashCode() { return ((1717635750 * -1521134295 + EqualityComparer<double>.Default.GetHashCode(X)) * -1521134295 + EqualityComparer<double>.Default.GetHashCode(Y)) * -1521134295 + EqualityComparer<double>.Default.GetHashCode(Z); } } Using Records: public class Demo { public void CreatePoint() { Point3D point3D = new Point3D(1.0, 1.0, 1.0); } } Records迎合了基于表达式形式编程的特性,使得我们可以这样使用它.var newPoint3D = Point3D.With(x: 42); 这样我们创建的新Point(new Point3D)就像现有的一个(point3D)一样并把X的值更改为42。这个特性于基于pattern matching也非常有效,我会在我的下一篇文章中介绍这一点.那么我们为什么要使用Records而不是用结构体呢?为了回答这些问题,我引用了了Reddit的一句话:“结构体是你必须要有一些约定来实现的东西。你不必手动地去让它只读,你也不用去实现他们的比较逻辑,但如果你不这样做,那你就失去了使用结构体的意义,编译器不会强制执行这些约束"。Records类型由是编译器实现,这意味着您必须满足所有这些条件并且不能错误, 因此,它们不仅可以减少重复代码,还可以消除一大堆潜在的错误。此外,这个功能在F#中存在了十多年,其他语言如(Scala,Kotlin)也有类似的概念。F#type Greeter(name: string) = member this.SayHi() = printfn "Hi, %s" name Scalaclass Greeter(name: String) { def SayHi() = println("Hi, " + name) } Kotlinclass Greeter(val name: String) { fun sayhi() { println("Hi, ${name}"); } } 在没有Records之前,我们要实现类似的功能,C#代码要这么写C#public class Greeter { private readonly string _name; public Greeter(string name) { _name = name; } public void Greet() { Console.WriteLine($ "Hello, {_name}"); } } 有了Records之后,我们可以将C#代码大大地减少了,ublic class Greeter(name: string) { public void Greet() { Console.WriteLine($ "Hello, {_name}"); } } Less code! = I love it!Type Classes此功能的灵感来自Haskell,它是我最喜欢的功能之一。正如我两年前在我文章中所说,C#将实现更多的函数式编(FP)程概念,Type Classes就是FP概念之一。在函数式编程中,Type Classes允许您在类型上添加一组操作,但不实现它。由于实现是在其他地方完成的,这是一种多态,它比面向对象编程语言中的class更灵活。Type Classes和C#接口具有相似的用途,但它们的工作方式有所不同,在某些情况下,由于处理固定类型而不是继承层次结构,因此Type Classes更易于使用。此这特性最初与“extending everything”功能一起引入,您可以将它们组合在一起,如Mads Torgersen给出的例子所示。我引用了官方提案中的一些结论:“一般来说,”shape“(shape是Type Classes的一个新的关键字)声明非常类似于接口声明,除了以下情况, 它可以定义任何类型的成员(包括静态成员) 可以通过扩展实现 只能在指定的地方当作一种类型使用(作用域)“ Haskell中 Type Classes示例。class Eq a where (==) :: a -> a -> Bool (/=) :: a -> a -> Bool “Eq”是类名,而==,/ =是类中的操作。类型“a”是类“Eq”的实例。如果我们将上述例子用C#接口实现将会是这样.interface Num<A> { A Add(A a, A b); A Mult(A a, A b); A Neg(A a); } struct NumInt : Num<int> { public int Add(int a, int b) => a + b; public int Mult(int a, int b) => a * b; public int Neg(int a) => -a; } 如果我们用Type Classes实现C# 功能会是这样shape Num<A> { A Add(A a, A b); A Mult(A a, A b); A Neg(A a); } instance NumInt : Num<int> { int Add(int a, int b) => a + b; int Mult(int a, int b) => a * b; int Neg(int a) => -a; } 通过上面例子,可以看到接口和shape的语法类似 ,那我们再来看看Mads Torgersen给出的例子Note:shape不是一种类型。相反,shape的主要目的是用作通用约束,限制类型参数以具有正确的形状,同时允许通用声明的主体使用该形状,原始来源public shape SGroup<T> { static T operator +(T t1, T t2); static T Zero {get;} } 这个声明说如果一个类型在T上实现了一个+运算符并且具有0静态属性,那么它可以是一个SGroup 。给int添加静态成员Zeropublic extension IntGroup of int: SGroup<int> { public static int Zero => 0; } 定义一个AddAll方法public static AddAll<T>(T[] ts) where T: SGroup<T> // shape used as constraint { var result = T.Zero; // Making use of the shape's Zero property foreach (var t in ts) { result += t; } // Making use of the shape's + operator return result; } 让我们用一些整数调用AddAll方法,int[] numbers = { 5, 1, 9, 2, 3, 10, 8, 4, 7, 6 }; WriteLine(AddAll(numbers)); // infers T = int 这就是Type class 的妙处,慢慢消化感受一下??Dictionary Literals引入更简单的语法来创建初始化的Dictionary <TKey,TValue>对象,而无需指定Dictionary类型名称或类型参数。使用用于数组类型推断的现有规则推断字典的类型参数。// C# 1..8 var x = new Dictionary <string,int> () { { "foo", 4 }, { "bar", 5 }}; // C# 9 var x = ["foo":4, "bar": 5]; 该特性使C#中的字典工作更简单,并删除冗余代码。此外,值得一提的是,在F#和Swift等其他编程语言中也使用了类似的字典语法。Params Span 允许params语法使用Span 这个帮助来实现没有任何堆分配的params参数传递。此功能可以使params方法的使用更加高效。新的语法如下,void Foo(params Span<int> values); struct允许使用无参构造函数到目前为止,在C#中不允许在结构体声明中使用无参构造函数,在C#9中,将删除此限制。StackOverflow示例public struct Rational { private long numerator; private long denominator; public Rational(long num, long denom) { /* Todo: Find GCD etc. */ } public Rational(long num) { numerator = num; denominator = 1; } public Rational() // This is not allowed { numerator = 0; denominator = 1; } } 链接到StackOverflow示例其实CLR已经允许值类型数据具有无参构造函数,只是C# 对这个功能进行了限制,在C# 9.0中可能会消除这种限制.固定大小的缓冲区这些提供了一种通用且安全的机制,用于向C#语言声明固定大小的缓冲区。目前,用户可以在不安全的环境中创建固定大小的缓冲区。但是,这需要用户处理指针,手动执行边界检查,并且只支持一组有限的类型(bool,byte,char,short,int,long,sbyte,ushort,uint,ulong,float和double)。该特性引入后将使固定大小的缓冲区变得安全安全,如下例所示。可以通过以下方式声明一个安全的固定大小的缓冲区,public fixed DXGI_RGB GammaCurve[1025]; 该声明将由编译器转换为内部表示,类似于以下内容,[FixedBuffer(typeof(DXGI_RGB), 1024)] public ConsoleApp1.<Buffer>e__FixedBuffer_1024<DXGI_RGB> GammaCurve; // Pack = 0 is the default packing and should result in indexable layout. [CompilerGenerated, UnsafeValueType, StructLayout(LayoutKind.Sequential, Pack = 0)] struct <Buffer>e__FixedBuffer_1024<T> { private T _e0; private T _e1; // _e2 ... _e1023 private T _e1024; public ref T this[int index] => ref (uint)index <= 1024u ? ref RefAdd<T>(ref _e0, index): throw new IndexOutOfRange(); } Uft8字符串文字它是关于定义一种新的字符串类型UTF8String,它将是,System.UTF8String myUTF8string ="Test String"; Base(T)此功能用于解决默认接口方法中的覆盖冲突问题:interface I1 { void M(int) { } } interface I2 { void M(short) { } } interface I3 { override void I1.M(int) { } } interface I4 : I3 { void M2() { base(I3).M(0) // Which M should be used here? What does this do? } } 更多信息, https://github.com/dotnet/csharplang/issues/2337 https://github.com/dotnet/csharplang/blob/master/meetings/2019/LDM-2019-02-27.md 摘要您已经阅读了第一个C#9候选特性。正如您所看到的,许多新功能受到其他编程语言或编程范例的启发,而不是自我创新,这些特性大部分在在社区中得到了广泛认可,所以引入C# 后应该也会给大家带来不错的体验.原文 : https://www.c-sharpcorner.com/article/candidate-features-for-c-sharp-9/ -
浅析 .Net Core中Json配置的自动更新 Pre很早在看 Jesse 的Asp.net Core快速入门的课程的时候就了解到了在Asp .net core中,如果添加的Json配置被更改了,是支持自动重载配置的,作为一名有着严重"造轮子"情节的程序员,最近在折腾一个博客系统,也想造出一个这样能自动更新以Mysql为数据源的ConfigureSource,于是点开了AddJsonFile这个拓展函数的源码,发现别有洞天,蛮有意思,本篇文章就简单地聊一聊Json config的ReloadOnChange是如何实现的,在学习ReloadOnChange的过程中,我们会把Configuration也顺带撩一把😁,希望对小伙伴们有所帮助. public static IWebHostBuilder CreateWebHostBuilder(string[] args) => WebHost.CreateDefaultBuilder(args) .ConfigureAppConfiguration(option => { option.AddJsonFile("appsettings.json",optional:true,reloadOnChange:true); }) .UseStartup<Startup>(); 在Asp .net core中如果配置了json数据源,把reloadOnChange属性设置为true即可实现当文件变更时自动更新配置,这篇博客我们首先从它的源码简单看一下,看完你可能还是会有点懵的,别慌,我会对这些代码进行精简,做个简单的小例子,希望能对你有所帮助.一窥源码AddJson首先,我们当然是从这个我们耳熟能详的扩展函数开始,它经历的演变过程如下. public static IConfigurationBuilder AddJsonFile(this IConfigurationBuilder builder,string path,bool optional,bool reloadOnChange) { return builder.AddJsonFile((IFileProvider) null, path, optional, reloadOnChange); } 传递一个null的FileProvider给另外一个重载Addjson函数.敲黑板,Null的FileProvider很重要,后面要考😄. public static IConfigurationBuilder AddJsonFile(this IConfigurationBuilder builder,IFileProvider provider,string path,bool optional,bool reloadOnChange) { return builder.AddJsonFile((Action<JsonConfigurationSource>) (s => { s.FileProvider = provider; s.Path = path; s.Optional = optional; s.ReloadOnChange = reloadOnChange; s.ResolveFileProvider(); })); } 把传入的参数演变成一个Action委托给JsonConfigurationSource的属性赋值. public static IConfigurationBuilder AddJsonFile(this IConfigurationBuilder builder, Action<JsonConfigurationSource> configureSource) { return builder.Add<JsonConfigurationSource>(configureSource); } 最终调用的builder.add(action)方法. public static IConfigurationBuilder Add<TSource>(this IConfigurationBuilder builder,Action<TSource> configureSource)where TSource : IConfigurationSource, new() { TSource source = new TSource(); if (configureSource != null) configureSource(source); return builder.Add((IConfigurationSource) source); } 在Add方法里,创建了一个Source实例,也就是JsonConfigurationSource实例,然后把这个实例传为刚刚的委托,这样一来,我们在最外面传入的"appsettings.json",optional:true,reloadOnChange:true参数就作用到这个示例上了.最终,这个实例添加到builder中.那么builder又是什么?它能干什么?ConfigurationBuild前面提及的builder默认情况下是ConfigurationBuilder,我对它的进行了简化,关键代码如下.public class ConfigurationBuilder : IConfigurationBuilder { public IList<IConfigurationSource> Sources { get; } = new List<IConfigurationSource>(); public IConfigurationBuilder Add(IConfigurationSource source) { Sources.Add(source); return this; } public IConfigurationRoot Build() { var providers = new List<IConfigurationProvider>(); foreach (var source in Sources) { var provider = source.Build(this); providers.Add(provider); } return new ConfigurationRoot(providers); } } 可以看到,这个builder中有个集合类型的Sources,这个Sources可以保存任何实现了IConfigurationSource的Source,前面聊到的JsonConfigurationSource就是实现了这个接口,常用的还有MemoryConfigurationSource,XmlConfigureSource,CommandLineConfigurationSource等.另外,它有一个很重要的build方法,这个build方法在WebHostBuilder方法执行build的时候也被调用,不要问我WebHostBuilder.builder方法什么执行的😂.public static void Main(string[] args) { CreateWebHostBuilder(args).Build().Run(); } 在ConfigureBuilder的方法里面就调用了每个Source的Builder方法,我们刚刚传入的是一个JsonConfigurationSource,所以我们有必要看看JsonSource的builder做了什么.这里是不是被这些builder绕哭了? 别慌,下一篇文章中我会讲解如何自定义一个ConfigureSoure,会把Congigure系列类UML类图整理一下,应该会清晰很多.JsonConfigurationSource public class JsonConfigurationSource : FileConfigurationSource { public override IConfigurationProvider Build(IConfigurationBuilder builder) { EnsureDefaults(builder); return new JsonConfigurationProvider(this); } } 这就是JsonConfigurationSource的所有代码,未精简,它只实现了一个Build方法,在Build内,EnsureDefaults被调用,可别小看它,之前那个空的FileProvider在这里被赋值了. public void EnsureDefaults(IConfigurationBuilder builder) { FileProvider = FileProvider ?? builder.GetFileProvider(); } public static IFileProvider GetFileProvider(this IConfigurationBuilder builder) { return new PhysicalFileProvider(AppContext.BaseDirectory ?? string.Empty); } 可以看到这个FileProvider默认情况下就是PhysicalFileProvider,为什么对这个FileProvider如此宠幸让我花如此大的伏笔要强调它呢?往下看.JsonConfigurationProvider && FileConfigurationProvider在JsonConfigurationSource的build方法内,返回的是一个JsonConfigurationProvider实例,所以直觉告诉我,在它的构造函数内必有猫腻😕. public class JsonConfigurationProvider : FileConfigurationProvider { public JsonConfigurationProvider(JsonConfigurationSource source) : base(source) { } public override void Load(Stream stream) { try { Data = JsonConfigurationFileParser.Parse(stream); } catch (JsonReaderException e) { throw new FormatException(Resources.Error_JSONParseError, e); } } } 看不出什么的代码,事出反常必有妖~~看看base的构造函数. public FileConfigurationProvider(FileConfigurationSource source) { Source = source; if (Source.ReloadOnChange && Source.FileProvider != null) { _changeTokenRegistration = ChangeToken.OnChange( () => Source.FileProvider.Watch(Source.Path), () => { Thread.Sleep(Source.ReloadDelay); Load(reload: true); }); } } 真是个天才,问题就在这个构造函数里,它构造函数调用了一个ChangeToken.OnChange方法,这是实现ReloadOnChange的关键,如果你点到这里还没有关掉,恭喜,好戏开始了.ReloadOnChangeTalk is cheap. Show me the code (屁话少说,放码过来). public static class ChangeToken { public static ChangeTokenRegistration<Action> OnChange(Func<IChangeToken> changeTokenProducer, Action changeTokenConsumer) { return new ChangeTokenRegistration<Action>(changeTokenProducer, callback => callback(), changeTokenConsumer); } } OnChange方法里,先不管什么func,action,就看看这两个参数的名称,producer,consumer,生产者,消费者,不知道看到这个关键词想到的是什么,反正我想到的是小学时学习食物链时的🐍与🐀.那么我们来看看这里的🐍是什么,🐀又是什么,还得回到FileConfigurationProvider的构造函数.可以看到生产者🐀是:() => Source.FileProvider.Watch(Source.Path) 消费者🐍是: () => { Thread.Sleep(Source.ReloadDelay); Load(reload: true); } 我们想一下,一旦有一条🐀跑出来,就立马被🐍吃了,那我们这里也一样,一旦有FileProvider.Watch返回了什么东西,就会发生Load()事件来重新加载数据.🐍与🐀好理解,可是代码就没那么好理解了,我们通过OnChange的第一个参数Func<IChangeToken> changeTokenProducer方法知道,这里的🐀,其实是IChangeToken.IChangeToken public interface IChangeToken { bool HasChanged { get; } bool ActiveChangeCallbacks { get; } IDisposable RegisterChangeCallback(Action<object> callback, object state); } IChangeToken的重点在于里面有个RegisterChangeCallback方法,🐍吃🐀的这件事,就发生在这回调方法里面.我们来做个🐍吃🐀的实验.实验1 static void Main() { //定义一个C:\Users\liuzh\MyBox\TestSpace目录的FileProvider var phyFileProvider = new PhysicalFileProvider("C:\\Users\\liuzh\\MyBox\\TestSpace"); //让这个Provider开始监听这个目录下的所有文件 var changeToken = phyFileProvider.Watch("*.*"); //注册🐍吃🐀这件事到回调函数 changeToken.RegisterChangeCallback(_=> { Console.WriteLine("老鼠被蛇吃"); }, new object()); //添加一个文件到目录 AddFileToPath(); Console.ReadKey(); } static void AddFileToPath() { Console.WriteLine("老鼠出洞了"); File.Create("C:\\Users\\liuzh\\MyBox\\TestSpace\\老鼠出洞了.txt").Dispose(); } 这是运行结果可以看到,一旦在监听的目录下创建文件,立即触发了执行回调函数,但是如果我们继续手动地更改(复制)监听目录中的文件,回调函数就不再执行了.这是因为changeToken监听到文件变更并触发回调函数后,这个changeToken的使命也就完成了,要想保持一直监听,那么我们就在在回调函数中重新获取token,并给新的token的回调函数注册通用的事件,这样就能保持一直监听下去了.这也就是ChangeToken.Onchange所作的事情,我们看一下源码. public static class ChangeToken { public static ChangeTokenRegistration<Action> OnChange(Func<IChangeToken> changeTokenProducer, Action changeTokenConsumer) { return new ChangeTokenRegistration<Action>(changeTokenProducer, callback => callback(), changeTokenConsumer); } } public class ChangeTokenRegistration<TAction> { private readonly Func<IChangeToken> _changeTokenProducer; private readonly Action<TAction> _changeTokenConsumer; private readonly TAction _state; public ChangeTokenRegistration(Func<IChangeToken> changeTokenProducer, Action<TAction> changeTokenConsumer, TAction state) { _changeTokenProducer = changeTokenProducer; _changeTokenConsumer = changeTokenConsumer; _state = state; var token = changeTokenProducer(); RegisterChangeTokenCallback(token); } private void RegisterChangeTokenCallback(IChangeToken token) { token.RegisterChangeCallback(_ => OnChangeTokenFired(), this); } private void OnChangeTokenFired() { var token = _changeTokenProducer(); try { _changeTokenConsumer(_state); } finally { // We always want to ensure the callback is registered RegisterChangeTokenCallback(token); } } } 简单来说,就是给token注册了一个OnChangeTokenFired的回调函数,仔细看看OnChangeTokenFired里做了什么,总体来说三步. 获取一个新的token. 调用消费者进行消费. 给新获取的token再次注册一个OnChangeTokenFired的回调函数. 如此周而复始~~实验2既然知道了OnChange的工作方式,那么我们把实验1的代码修改一下. static void Main() { var phyFileProvider = new PhysicalFileProvider("C:\\Users\\liuzh\\MyBox\\TestSpace"); ChangeToken.OnChange(() => phyFileProvider.Watch("*.*"), () => { Console.WriteLine("老鼠被蛇吃"); }); Console.ReadKey(); } 执行效果看一下可以看到,只要被监控的目录发生了文件变化,不管是新建文件,还是修改了文件内的内容,都会触发回调函数,其实JsonConfig中,这个回调函数就是Load(),它负责重新加载数据,可也就是为什么Asp .net core中如果把ReloadOnchang设置为true后,Json的配置一旦更新,配置就会自动重载.PhysicalFilesWatcher那么,为什么文件一旦变化,就会触发ChangeToken的回调函数呢? 其实PhysicalFileProvider中调用了PhysicalFilesWatcher对文件系统进行监视,观察PhysicalFilesWatcher的构造函数,可以看到PhysicalFilesWatcher需要传入FileSystemWatcher,FileSystemWatcher是system.io下的底层IO类,在构造函数中给这个Watcher的Created,Changed,Renamed,Deleted注册EventHandler事件,最终,在这些EventHandler中会调用ChangToken的回调函数,所以文件系统一旦发生变更就会触发回调函数. public PhysicalFilesWatcher(string root,FileSystemWatcher fileSystemWatcher,bool pollForChanges,ExclusionFilters filters) { this._root = root; this._fileWatcher = fileSystemWatcher; this._fileWatcher.IncludeSubdirectories = true; this._fileWatcher.Created += new FileSystemEventHandler(this.OnChanged); this._fileWatcher.Changed += new FileSystemEventHandler(this.OnChanged); this._fileWatcher.Renamed += new RenamedEventHandler(this.OnRenamed); this._fileWatcher.Deleted += new FileSystemEventHandler(this.OnChanged); this._fileWatcher.Error += new ErrorEventHandler(this.OnError); this.PollForChanges = pollForChanges; this._filters = filters; this.PollingChangeTokens = new ConcurrentDictionary<IPollingChangeToken, IPollingChangeToken>(); this._timerFactory = (Func<Timer>) (() => NonCapturingTimer.Create(new TimerCallback(PhysicalFilesWatcher.RaiseChangeEvents), (object) this.PollingChangeTokens, TimeSpan.Zero, PhysicalFilesWatcher.DefaultPollingInterval)); } 蒋金楠老师有一篇优秀的文章介绍FileProvider,有兴趣的可以看一下https://www.cnblogs.com/artech/p/net-core-file-provider-02.html.如果你和我一样,对源码感兴趣,可以从官方的aspnet/Extensions中下载源码研究:https://github.com/aspnet/Extensions在下一篇文章中,我会讲解如何自定义一个以Mysql为数据源的ConfigureSoure,并实现自动更新功能,同时还会整理Configure相关类的UML类图,有兴趣的可以关注我以便第一时间收到下篇文章.本文章涉及的代码地址:https://github.com/liuzhenyulive/MiniConfiguration
-
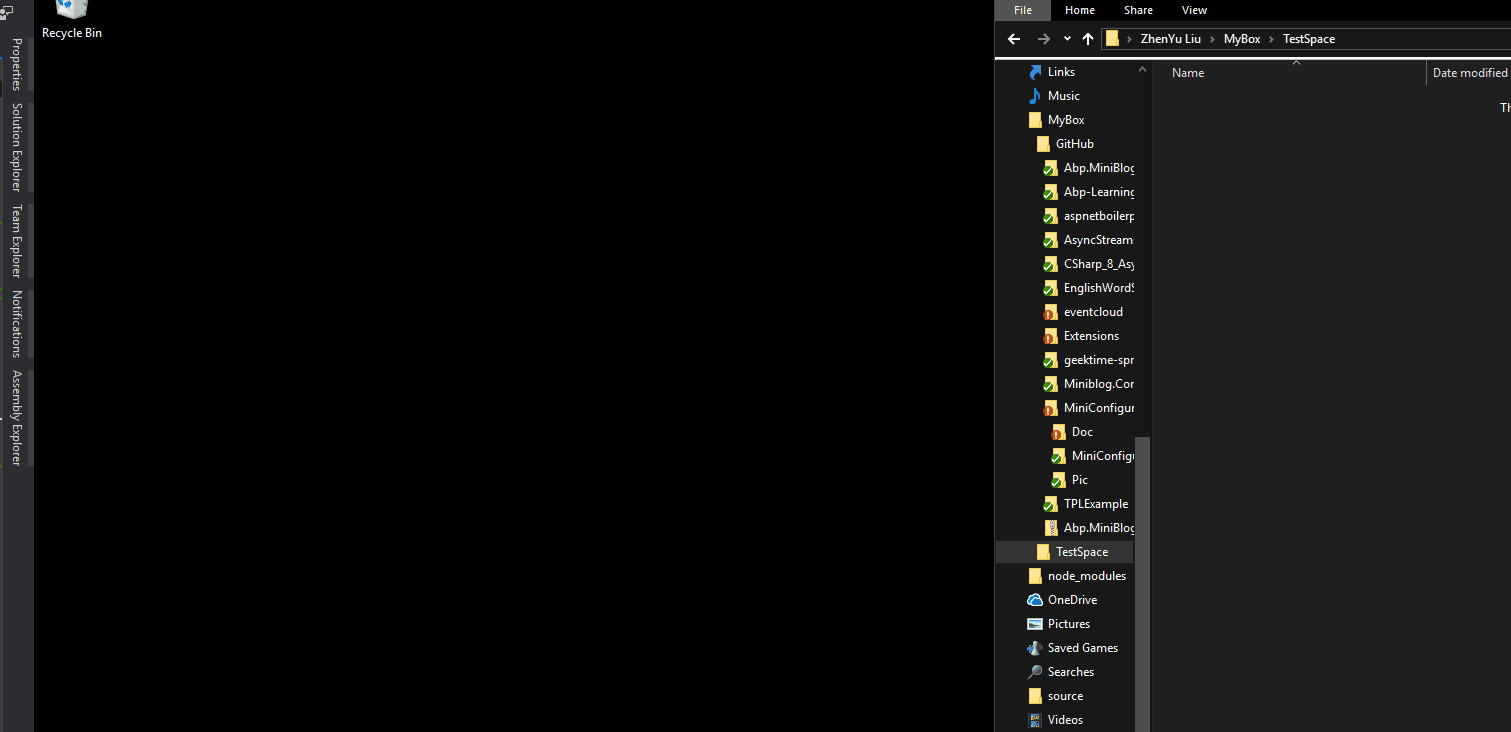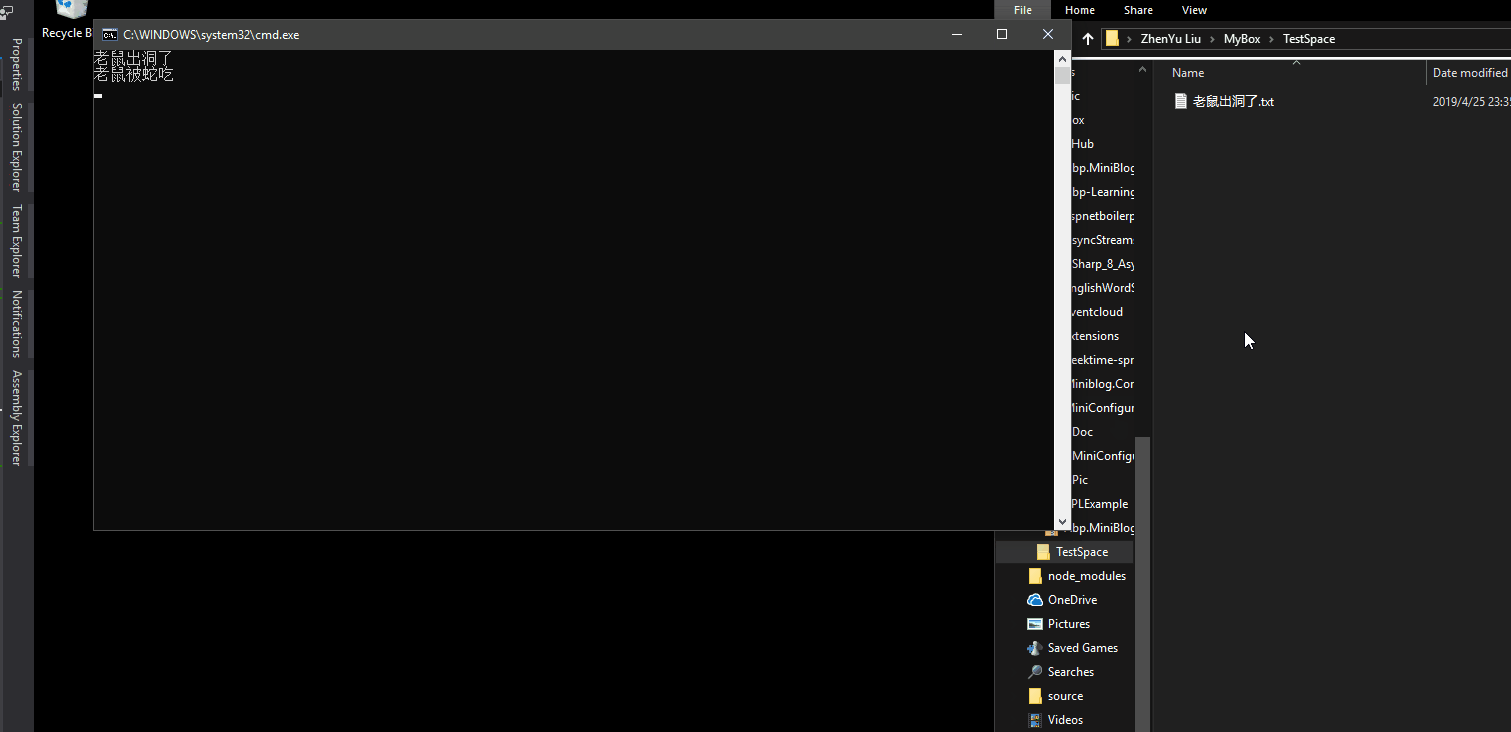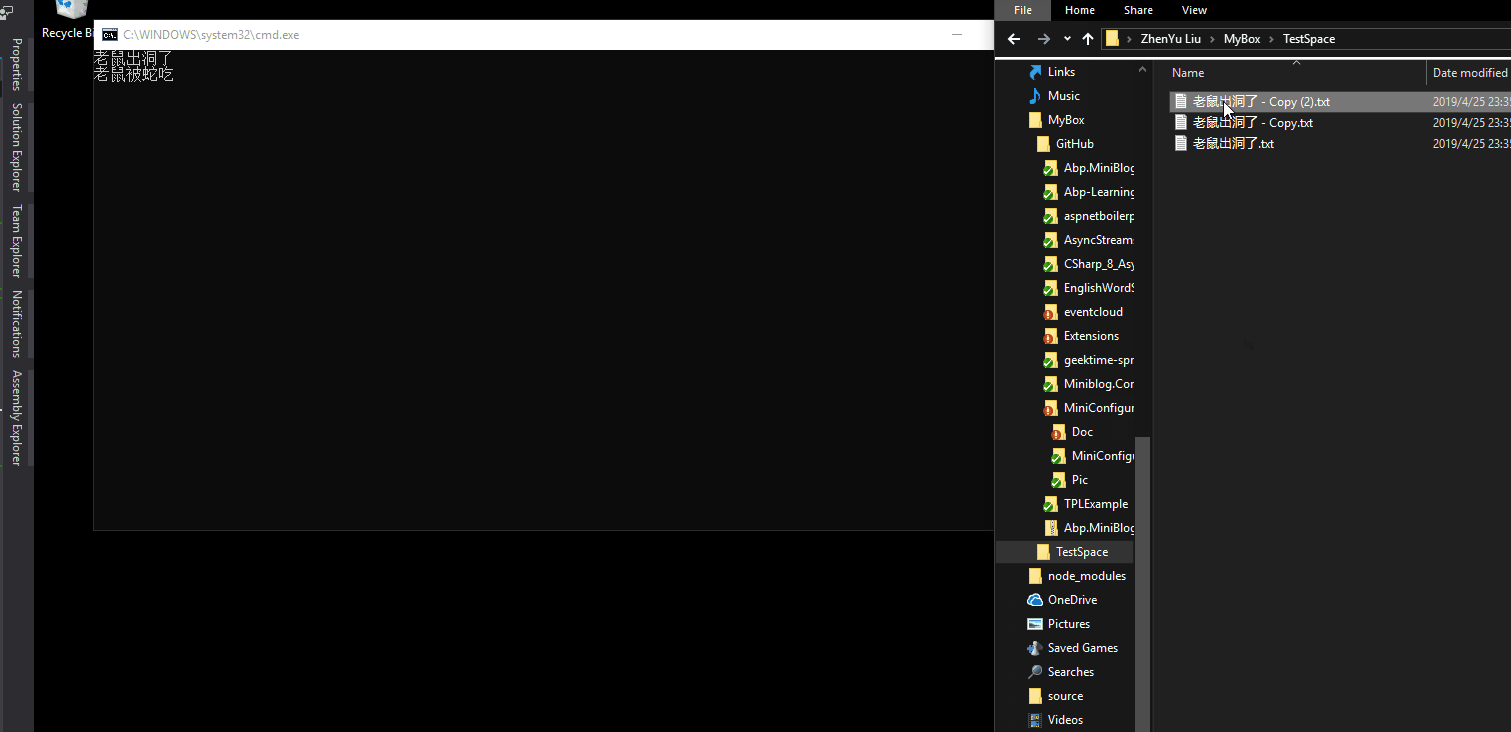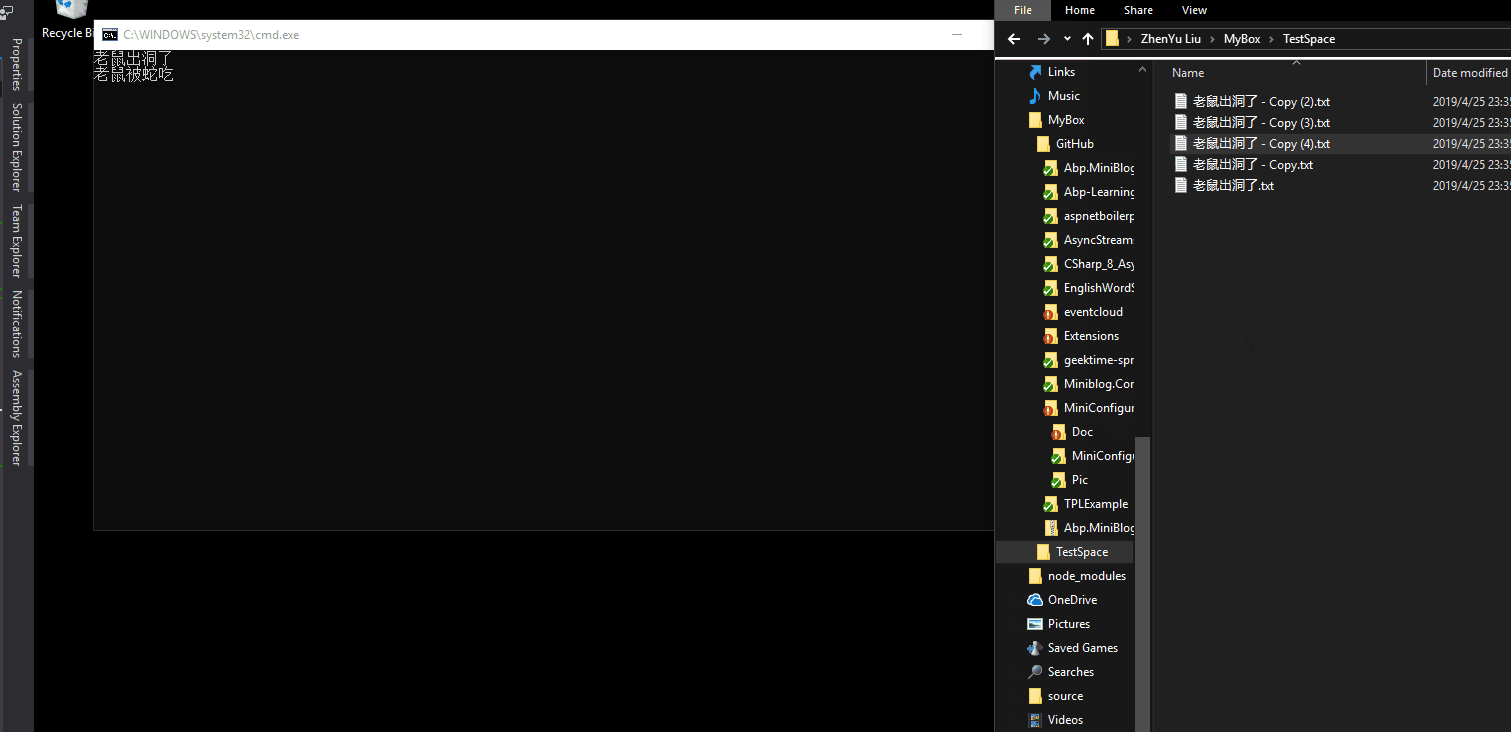
聊一聊C# 8.0中的await foreach AsyncStreamsInCShaper8.0很开心今天能与大家一起聊聊C# 8.0中的新特性-Async Streams,一般人通常看到这个词表情是这样.简单说,其实就是C# 8.0中支持await foreach.或者说,C# 8.0中支持异步返回枚举类型async Task<IEnumerable<T>>.好吧,还不懂?Good,这篇文章就是为你写的,看完这篇文章,你就能明白它的神奇之处了.为什么写这篇文章Async Streams这个功能已经发布很久了,在去年的Build 2018 The future of C#就有演示,最近VS 2019发布,在该版本的Release Notes中,我再次看到了这个新特性,因为对异步编程不太熟悉,所以借着这个机会,学习新特性的同时,把异步编程重温一遍.本文内容,参考了Bassam Alugili在InfoQ中发表的Async Streams in C# 8,撰写本博客前我已联系上该作者并得到他支持.Async / AwaitC# 5 引入了 Async/Await,用以提高用户界面响应能力和对 Web 资源的访问能力。换句话说,异步方法用于执行不阻塞线程并返回一个标量结果的异步操作。微软多次尝试简化异步操作,因为 Async/Await 模式易于理解,所以在开发人员当中获得了良好的认可。详见The Task asynchronous programming model in C#常规示例要了解问什么需要Async Streams,我们先来看看这样的一个示例,求出5以内的整数的和.static int SumFromOneToCount(int count) { ConsoleExt.WriteLine("SumFromOneToCount called!"); var sum = 0; for (var i = 0; i <= count; i++) { sum = sum + i; } return sum; } 调用方法.static void Main(string[] args) { const int count = 5; ConsoleExt.WriteLine($"Starting the application with count: {count}!"); ConsoleExt.WriteLine("Classic sum starting."); ConsoleExt.WriteLine($"Classic sum result: {SumFromOneToCount(count)}"); ConsoleExt.WriteLine("Classic sum completed."); ConsoleExt.WriteLine("################################################"); } 输出结果.可以看到,整个过程就一个线程Id为1的线程自上而下执行,这是最基础的做法.Yield Return接下来,我们使用yield运算符使得这个方法编程延迟加载,如下所示.static IEnumerable<int> SumFromOneToCountYield(int count) { ConsoleExt.WriteLine("SumFromOneToCountYield called!"); var sum = 0; for (var i = 0; i <= count; i++) { sum = sum + i; yield return sum; } } 主函数static void Main(string[] args) { const int count = 5; ConsoleExt.WriteLine("Sum with yield starting."); foreach (var i in SumFromOneToCountYield(count)) { ConsoleExt.WriteLine($"Yield sum: {i}"); } ConsoleExt.WriteLine("Sum with yield completed."); ConsoleExt.WriteLine("################################################"); ConsoleExt.WriteLine(Environment.NewLine); } 运行结果如下.正如你在输出窗口中看到的那样,结果被分成几个部分返回,而不是作为一个值返回。以上显示的累积结果被称为惰性枚举。但是,仍然存在一个问题,即 sum 方法阻塞了代码的执行。如果你查看线程ID,可以看到所有东西都在主线程1中运行,这显然不完美,继续改造.Async Return我们试着将async用于SumFromOneToCount方法(没有yield关键字).static async Task<int> SumFromOneToCountAsync(int count) { ConsoleExt.WriteLine("SumFromOneToCountAsync called!"); var result = await Task.Run(() => { var sum = 0; for (var i = 0; i <= count; i++) { sum = sum + i; } return sum; }); return result; } 主函数.static async Task Main(string[] args) { const int count = 5; ConsoleExt.WriteLine("async example starting."); // Sum runs asynchronously! Not enough. We need sum to be async with lazy behavior. var result = await SumFromOneToCountAsync(count); ConsoleExt.WriteLine("async Result: " + result); ConsoleExt.WriteLine("async completed."); ConsoleExt.WriteLine("################################################"); ConsoleExt.WriteLine(Environment.NewLine); } 运行结果.我们可以看到计算过程是在另一个线程中运行,但结果仍然是作为一个值返回!任然不完美.如果我们想把惰性枚举(yield return)与异步方法结合起来,即返回Task<IEnumerable,这怎么实现呢?Task<IEnumerable>我们根据假设把代码改造一遍,使用Task<IEnumerable<T>>来进行计算.可以看到,直接出现错误.IAsyncEnumerable其实,在C# 8.0中Task<IEnumerable>这种组合称为IAsyncEnumerable。这个新功能为我们提供了一种很好的技术来解决拉异步延迟加载的问题,例如从网站下载数据或从文件或数据库中读取记录,与 IEnumerable 和 IEnumerator 类似,Async Streams 提供了两个新接口 IAsyncEnumerable 和 IAsyncEnumerator,定义如下:public interface IAsyncEnumerable<out T> { IAsyncEnumerator<T> GetAsyncEnumerator(); } public interface IAsyncEnumerator<out T> : IAsyncDisposable { Task<bool> MoveNextAsync(); T Current { get; } } // Async Streams Feature 可以被异步销毁 public interface IAsyncDisposable { Task DiskposeAsync(); } AsyncStream下面,我们就来见识一下AsyncStrema的威力,我们使用IAsyncEnumerable来对函数进行改造,如下.static async Task ConsumeAsyncSumSeqeunc(IAsyncEnumerable<int> sequence) { ConsoleExt.WriteLineAsync("ConsumeAsyncSumSeqeunc Called"); await foreach (var value in sequence) { ConsoleExt.WriteLineAsync($"Consuming the value: {value}"); // simulate some delay! await Task.Delay(TimeSpan.FromSeconds(1)); }; } private static async IAsyncEnumerable<int> ProduceAsyncSumSeqeunc(int count) { ConsoleExt.WriteLineAsync("ProduceAsyncSumSeqeunc Called"); var sum = 0; for (var i = 0; i <= count; i++) { sum = sum + i; // simulate some delay! await Task.Delay(TimeSpan.FromSeconds(0.5)); yield return sum; } } 主函数. static async Task Main(string[] args) { const int count = 5; ConsoleExt.WriteLine("Starting Async Streams Demo!"); // Start a new task. Used to produce async sequence of data! IAsyncEnumerable<int> pullBasedAsyncSequence = ProduceAsyncSumSeqeunc(count); // Start another task; Used to consume the async data sequence! var consumingTask = Task.Run(() => ConsumeAsyncSumSeqeunc(pullBasedAsyncSequence)); await Task.Delay(TimeSpan.FromSeconds(3)); ConsoleExt.WriteLineAsync("X#X#X#X#X#X#X#X#X#X# Doing some other work X#X#X#X#X#X#X#X#X#X#"); // Just for demo! Wait until the task is finished! await consumingTask; ConsoleExt.WriteLineAsync("Async Streams Demo Done!"); } 如果一切顺利,那么就能看到这样的运行结果了.最后,看到这就是我们想要的结果,在枚举的基础上,进行了异步迭代.可以看到,整个计算过程并没有造成主线程的阻塞,其中,值得重点关注的是红色方框区域的线程5!线程5!线程5!线程5在请求下一个结果后,并没有等待结果返回,而是去了Main()函数中做了别的事情,等待请求的结果返回后,线程5又接着执行foreach中任务.Client/Server的异步拉取如果还没有理解Async Streams的好处,那么我借助客户端 / 服务器端架构是演示这一功能优势的绝佳方法。同步调用客户端向服务器端发送请求,客户端必须等待(客户端被阻塞),直到服务器端做出响应.示例中Yield Return就是以这种方式执行的,所以整个过程只有一个线程即线程1在处理.异步调用客户端发出数据块请求,然后继续执行其他操作。一旦数据块到达,客户端就处理接收到的数据块并询问下一个数据块,依此类推,直到达到最后一个数据块为止。这正是 Async Streams 想法的来源。最后一个示例就是以这种方式执行的,线程5询问下一个数据后并没有等待结果返回,而是去做了Main()函数中的别的事情,数据到达后,线程5又继续处理foreach中的任务.Tips如果你使用的是.net core 2.2及以下版本,会遇到这样的报错.需要安装.net core 3.0 preview的SDK(截至至博客撰写日期4月9日,.net core SDK最新版本为3.0.100-preview3-010431),安装好SDK后,如果你是VS 2019正式版,可能无法选择.net core 3.0,vs 2019 正式版默认情况下没有开启对预览版.net core 3.0 的支持.根据网友补充,需要在VS 2019正式版本中需要开启使用 .Net core SDK 预览版,才能创建3.0的项目.工具 > 选项 > 项目和解决方案 > .Net Core > 使用 .Net core SDK 预览版总结我们已经讨论过 Async Streams,它是一种出色的异步拉取技术,可用于进行生成多个值的异步计算。Async Streams 背后的编程概念是异步拉取模型。我们请求获取序列的下一个元素,并最终得到答复。Async Streams 提供了一种处理异步数据源的绝佳方法,希望对大家能够有所帮助。文章中涉及的所有代码已保存在我的GitHub中,请尽情享用!https://github.com/liuzhenyulive/AsyncStreamsInCShaper8.0致谢之前一直感觉国外的大师级开发者遥不可及甚至高高在上,在遇到Bassam Alugili之后,我才真正感受到技术交流没有高低贵贱,正如他对我说的 The most important thing in this world is sharing the knowledge!Thank you,I will keep going!!参考文献: Async Streams in C# 8 https://www.infoq.com/articles/Async-Streams
-
ConcurrentDictionary并发字典知多少 背景在上一篇文章你真的了解字典吗?一文中我介绍了Hash Function和字典的工作的基本原理.有网友在文章底部评论,说我的Remove和Add方法没有考虑线程安全问题.https://docs.microsoft.com/en-us/dotnet/api/system.collections.generic.dictionary-2?redirectedfrom=MSDN&view=netframework-4.7.2查阅相关资料后,发现字典.net中Dictionary本身时不支持线程安全的,如果要想使用支持线程安全的字典,那么我们就要使用ConcurrentDictionary了.在研究ConcurrentDictionary的源码后,我觉得在ConcurrentDictionary的线程安全的解决思路很有意思,其对线程安全的处理对对我们项目中的其他高并发场景也有一定的参考价值,在这里再次分享我的一些学习心得和体会,希望对大家有所帮助.ConcurrentConcurrentDictionary是Dictionary的线程安全版本,位于System.Collections.Concurrent的命名空间下,该命名空间下除了有ConcurrentDictionary,还有以下Class都是我们常用的那些类库的线程安全版本.BlockingCollection:为实现 IProducerConsumerCollection 的线程安全集合提供阻塞和限制功能。ConcurrentBag:表示对象的线程安全的无序集合.ConcurrentQueue:表示线程安全的先进先出 (FIFO) 集合。如果读过我上一篇文章你真的了解字典吗?的小伙伴,对这个ConcurrentDictionary的工作原理应该也不难理解,它是简简单单地在读写方法加个lock吗?工作原理Dictionary如下图所示,在字典中,数组entries用来存储数据,buckets作为桥梁,每次通过hash function获取了key的哈希值后,对这个哈希值进行取余,即hashResult%bucketsLength=bucketIndex,余数作为buckets的index,而buckets的value就是这个key对应的entry所在entries中的索引,所以最终我们就可以通过这个索引在entries中拿到我们想要的数据,整个过程不需要对所有数据进行遍历,的时间复杂度为1.ConcurrentDictionaryConcurrentDictionary的数据存储类似,只是buckets有个更多的职责,它除了有dictionary中的buckets的桥梁的作用外,负责了数据存储.key的哈希值与buckets的length取余后hashResult%bucketsLength=bucketIndex,余数作为buckets的索引就能找到我们要的数据所存储的块,当出现两个key指向同一个块时,即上图中的John Smith和Sandra Dee他同时指向152怎么办呢?存储节点Node具有Next属性执行下个Node,上图中,node 152的Next为154,即我们从152开始找Sandra Dee,发现不是我们想要的,再到154找,即可取到所需数据.由于官方原版的源码较为复杂,理解起来有所难度,我对官方源码做了一些精简,下文将围绕这个精简版的ConcurrentDictionary展开叙述.https://github.com/liuzhenyulive/DictionaryMini数据结构NodeConcurrentDictionary中的每个数据存储在一个Node中,它除了存储value信息,还存储key信息,以及key对应的hashcodeprivate class Node { internal TKey m_key; //数据的key internal TValue m_value; //数据值 internal volatile Node m_next; //当前Node的下级节点 internal int m_hashcode; //key的hashcode //构造函数 internal Node(TKey key, TValue value, int hashcode, Node next) { m_key = key; m_value = value; m_next = next; m_hashcode = hashcode; } } Table而整个ConcurrentDictionary的数据存储在这样的一个Table中,其中m_buckets的Index负责映射key,m_locks是线程锁,下文中会有详细介绍,m_countPerLock存储每个lock锁负责的node数量. private class Tables { internal readonly Node[] m_buckets; //上文中提到的buckets internal readonly object[] m_locks; //线程锁 internal volatile int[] m_countPerLock; //索格锁所管理的数据数量 internal readonly IEqualityComparer<TKey> m_comparer; //当前key对应的type的比较器 //构造函数 internal Tables(Node[] buckets, object[] locks, int[] countPerlock, IEqualityComparer<TKey> comparer) { m_buckets = buckets; m_locks = locks; m_countPerLock = countPerlock; m_comparer = comparer; } } ConcurrentDictionary会在构造函数中创建Table,这里我对原有的构造函数进行了简化,通过默认值进行创建,其中DefaultConcurrencyLevel默认并发级别为当前计算机处理器的线程数. //构造函数 public ConcurrentDictionaryMini() : this(DefaultConcurrencyLevel, DEFAULT_CAPACITY, true, EqualityComparer<TKey>.Default) { } /// <summary> /// /// </summary> /// <param name="concurrencyLevel">并发等级,默认为CPU的线程数</param> /// <param name="capacity">默认容量,31,超过31后会自动扩容</param> /// <param name="growLockArray">时否动态扩充锁的数量</param> /// <param name="comparer">key的比较器</param> internal ConcurrentDictionaryMini(int concurrencyLevel, int capacity, bool growLockArray, IEqualityComparer<TKey> comparer) { if (concurrencyLevel < 1) { throw new Exception("concurrencyLevel 必须为正数"); } if (capacity < 0) { throw new Exception("capacity 不能为负数."); } if (capacity < concurrencyLevel) { capacity = concurrencyLevel; } object[] locks = new object[concurrencyLevel]; for (int i = 0; i < locks.Length; i++) { locks[i] = new object(); } int[] countPerLock = new int[locks.Length]; Node[] buckets = new Node[capacity]; m_tables = new Tables(buckets, locks, countPerLock, comparer); m_growLockArray = growLockArray; m_budget = buckets.Length / locks.Length; } 方法ConcurrentDictionary中较为基础重点的方法分别位Add,Get,Remove,Grow Table方法,其他方法基本上是建立在这四个方法的基础上进行的扩充.Add向Table中添加元素有以下亮点值得我们关注. 开始操作前会声明一个tables变量来存储操作开始前的m_tables,在正式开始操作后(进入lock)的时候,会检查tables在准备工作阶段是否别的线程改变,如果改变了,则重新开始准备工作并从新开始. 通过GetBucketAndLockNo方法获取bucket索引以及lock索引,其内部就是取余操作. private void GetBucketAndLockNo( int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount) { //0x7FFFFFFF 是long int的最大值 与它按位与数据小于等于这个最大值 bucketNo = (hashcode & 0x7fffffff) % bucketCount; lockNo = bucketNo % lockCount; } 对数据进行操作前会从m_locks取出第lockNo个对象最为lock,操作完成后释放该lock.多个lock一定程度上减少了阻塞的可能性. 在对数据进行更新时,如果该Value的Type为允许原子性写入的,则直接更新该Value,否则创建一个新的node进行覆盖. /// <summary> /// Determines whether type TValue can be written atomically /// </summary> private static bool IsValueWriteAtomic() { Type valueType = typeof(TValue); // // Section 12.6.6 of ECMA CLI explains which types can be read and written atomically without // the risk of tearing. // // See http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-335.pdf // if (valueType.IsClass) { return true; } switch (Type.GetTypeCode(valueType)) { case TypeCode.Boolean: case TypeCode.Byte: case TypeCode.Char: case TypeCode.Int16: case TypeCode.Int32: case TypeCode.SByte: case TypeCode.Single: case TypeCode.UInt16: case TypeCode.UInt32: return true; case TypeCode.Int64: case TypeCode.Double: case TypeCode.UInt64: return IntPtr.Size == 8; default: return false; } } 该方法依据CLI规范进行编写,简单来说,32位的计算机,对32字节以下的数据类型写入时可以一次写入的而不需要移动内存指针,64位计算机对64位以下的数据可一次性写入,不需要移动内存指针.保证了写入的安全.详见12.6.6 http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-335.pdf private bool TryAddInternal(TKey key, TValue value, bool updateIfExists, bool acquireLock, out TValue resultingValue) { while (true) { int bucketNo, lockNo; int hashcode; //https://www.cnblogs.com/blurhkh/p/10357576.html //需要了解一下值传递和引用传递 Tables tables = m_tables; IEqualityComparer<TKey> comparer = tables.m_comparer; hashcode = comparer.GetHashCode(key); GetBucketAndLockNo(hashcode, out bucketNo, out lockNo, tables.m_buckets.Length, tables.m_locks.Length); bool resizeDesired = false; bool lockTaken = false; try { if (acquireLock) Monitor.Enter(tables.m_locks[lockNo], ref lockTaken); //如果表刚刚调整了大小,我们可能没有持有正确的锁,必须重试。 //当然这种情况很少见 if (tables != m_tables) continue; Node prev = null; for (Node node = tables.m_buckets[bucketNo]; node != null; node = node.m_next) { if (comparer.Equals(node.m_key, key)) { //key在字典里找到了。如果允许更新,则更新该key的值。 //我们需要为更新创建一个node,以支持不能以原子方式写入的TValue类型,因为free-lock 读取可能同时发生。 if (updateIfExists) { if (s_isValueWriteAtomic) { node.m_value = value; } else { Node newNode = new Node(node.m_key, value, hashcode, node.m_next); if (prev == null) { tables.m_buckets[bucketNo] = newNode; } else { prev.m_next = newNode; } } resultingValue = value; } else { resultingValue = node.m_value; } return false; } prev = node; } //key没有在bucket中找到,则插入该数据 Volatile.Write(ref tables.m_buckets[bucketNo], new Node(key, value, hashcode, tables.m_buckets[bucketNo])); //当m_countPerLock超过Int Max时会抛出OverflowException checked { tables.m_countPerLock[lockNo]++; } // // 如果m_countPerLock[lockNo] > m_budget,则需要调整buckets的大小。 // GrowTable也可能会增加m_budget,但不会调整bucket table的大小。. // 如果发现bucket table利用率很低,也会发生这种情况。 // if (tables.m_countPerLock[lockNo] > m_budget) { resizeDesired = true; } } finally { if (lockTaken) Monitor.Exit(tables.m_locks[lockNo]); } if (resizeDesired) { GrowTable(tables, tables.m_comparer, false, m_keyRehashCount); } resultingValue = value; return true; } } Get从Table中获取元素的的流程与前文介绍ConcurrentDictionary工作原理时一致,但有以下亮点值得关注. 读取bucket[i]在Volatile.Read()方法中进行,该方法会自动对读取出来的数据加锁,避免在读取的过程中,数据被其他线程remove了. Volatile读取指定字段时,在读取的内存中插入一个内存屏障,阻止处理器重新排序内存操作,如果在代码中此方法之后出现读取或写入,则处理器无法在此方法之前移动它。 public bool TryGetValue(TKey key, out TValue value) { if (key == null) throw new ArgumentNullException("key"); // We must capture the m_buckets field in a local variable. It is set to a new table on each table resize. Tables tables = m_tables; IEqualityComparer<TKey> comparer = tables.m_comparer; GetBucketAndLockNo(comparer.GetHashCode(key), out var bucketNo, out _, tables.m_buckets.Length, tables.m_locks.Length); // We can get away w/out a lock here. // The Volatile.Read ensures that the load of the fields of 'n' doesn't move before the load from buckets[i]. Node n = Volatile.Read(ref tables.m_buckets[bucketNo]); while (n != null) { if (comparer.Equals(n.m_key, key)) { value = n.m_value; return true; } n = n.m_next; } value = default(TValue); return false; } RemoveRemove方法实现其实也并不复杂,类似我们链表操作中移除某个Node.移除节点的同时,还要对前后节点进行链接,相信一块小伙伴们肯定很好理解. private bool TryRemoveInternal(TKey key, out TValue value, bool matchValue, TValue oldValue) { while (true) { Tables tables = m_tables; IEqualityComparer<TKey> comparer = tables.m_comparer; int bucketNo, lockNo; GetBucketAndLockNo(comparer.GetHashCode(key), out bucketNo, out lockNo, tables.m_buckets.Length, tables.m_locks.Length); lock (tables.m_locks[lockNo]) { if (tables != m_tables) continue; Node prev = null; for (Node curr = tables.m_buckets[bucketNo]; curr != null; curr = curr.m_next) { if (comparer.Equals(curr.m_key, key)) { if (matchValue) { bool valuesMatch = EqualityComparer<TValue>.Default.Equals(oldValue, curr.m_value); if (!valuesMatch) { value = default(TValue); return false; } } if (prev == null) Volatile.Write(ref tables.m_buckets[bucketNo], curr.m_next); else { prev.m_next = curr.m_next; } value = curr.m_value; tables.m_countPerLock[lockNo]--; return true; } prev = curr; } } value = default(TValue); return false; } } Grow table当table中任何一个m_countPerLock的数量超过了设定的阈值后,会触发此操作对Table进行扩容.private void GrowTable(Tables tables, IEqualityComparer<TKey> newComparer, bool regenerateHashKeys, int rehashCount) { int locksAcquired = 0; try { //首先锁住第一个lock进行resize操作. AcquireLocks(0, 1, ref locksAcquired); if (regenerateHashKeys && rehashCount == m_keyRehashCount) { tables = m_tables; } else { if (tables != m_tables) return; long approxCount = 0; for (int i = 0; i < tables.m_countPerLock.Length; i++) { approxCount += tables.m_countPerLock[i]; } //如果bucket数组太空,则将预算加倍,而不是调整表的大小 if (approxCount < tables.m_buckets.Length / 4) { m_budget = 2 * m_budget; if (m_budget < 0) { m_budget = int.MaxValue; } return; } } int newLength = 0; bool maximizeTableSize = false; try { checked { newLength = tables.m_buckets.Length * 2 + 1; while (newLength % 3 == 0 || newLength % 5 == 0 || newLength % 7 == 0) { newLength += 2; } } } catch (OverflowException) { maximizeTableSize = true; } if (maximizeTableSize) { newLength = int.MaxValue; m_budget = int.MaxValue; } AcquireLocks(1, tables.m_locks.Length, ref locksAcquired); object[] newLocks = tables.m_locks; //Add more locks if (m_growLockArray && tables.m_locks.Length < MAX_LOCK_NUMBER) { newLocks = new object[tables.m_locks.Length * 2]; Array.Copy(tables.m_locks, newLocks, tables.m_locks.Length); for (int i = tables.m_locks.Length; i < newLocks.Length; i++) { newLocks[i] = new object(); } } Node[] newBuckets = new Node[newLength]; int[] newCountPerLock = new int[newLocks.Length]; for (int i = 0; i < tables.m_buckets.Length; i++) { Node current = tables.m_buckets[i]; while (current != null) { Node next = current.m_next; int newBucketNo, newLockNo; int nodeHashCode = current.m_hashcode; if (regenerateHashKeys) { //Recompute the hash from the key nodeHashCode = newComparer.GetHashCode(current.m_key); } GetBucketAndLockNo(nodeHashCode, out newBucketNo, out newLockNo, newBuckets.Length, newLocks.Length); newBuckets[newBucketNo] = new Node(current.m_key, current.m_value, nodeHashCode, newBuckets[newBucketNo]); checked { newCountPerLock[newLockNo]++; } current = next; } } if (regenerateHashKeys) { unchecked { m_keyRehashCount++; } } m_budget = Math.Max(1, newBuckets.Length / newLocks.Length); m_tables = new Tables(newBuckets, newLocks, newCountPerLock, newComparer); } finally { ReleaseLocks(0, locksAcquired); } } 学习感悟 lock[]:在以往的线程安全上,我们对数据的保护往往是对数据的修改写入等地方加上lock,这个lock经常上整个上下文中唯一的,这样的设计下就可能会出现多个线程,写入的根本不是一块数据,却要等待前一个线程写入完成下一个线程才能继续操作.在ConcurrentDictionary中,通过哈希算法,从数组lock[]中找出key的准确lock,如果不同的key,使用的不是同一个lock,那么这多个线程的写入时互不影响的. 写入要考虑线程安全,读取呢?不可否认,在大部分场景下,读取不必去考虑线程安全,但是在我们这样的链式读取中,需要自上而下地查找,是不是有种可能在查找个过程中,链路被修改了呢?所以ConcurrentDictionary中使用Volatile.Read来读取出数据,该方法从指定字段读取对象引用,在需要它的系统上,插入一个内存屏障,阻止处理器重新排序内存操作,如果在代码中此方法之后出现读取或写入,则处理器无法在此方法之前移动它。 在ConcurrentDictionary的更新方法中,对数据进行更新时,会判断该数据是否可以原子写入,如果时可以原子写入的,那么就直接更新数据,如果不是,那么会创建一个新的node覆盖原有node,起初看到这里时候,我百思不得其解,不知道这么操作的目的,后面在jeo duffy的博客中Thread-safety, torn reads, and the like中找到了答案,这样操作时为了防止torn reads(撕裂读取),什么叫撕裂读取呢?通俗地说,就是有的数据类型写入时,要分多次写入,写一次,移动一次指针,那么就有可能写了一半,这个结果被另外一个线程读取走了.比如说我把 刘振宇三个字改成周杰伦的过程中,我先把刘改成周了,正在我准备去把振改成杰的时候,另外一个线程过来读取结果了,读到的数据是周振宇,这显然是不对的.所以对这种,更安全的做法是先把周杰伦三个字写好在一张纸条上,然后直接替换掉刘振宇.更多信息在CLI规范12.6.6有详细介绍. checked和unckecked关键字.非常量的运算(non-constant)运算在编译阶段和运行时下不会做溢出检查,如下这样的代码时不会抛出异常的,算错了也不会报错。 int ten = 10; int i2 = 2147483647 + ten; 但是我们知道,int的最大值是2147483647,如果我们将上面这样的代码嵌套在checked就会做溢出检查了.checked { int ten = 10; int i2 = 2147483647 + ten; } 相反,对于常量,编译时是会做溢出检查的,下面这样的代码在编译时就会报错的,如果我们使用unckeck标签进行标记,则在编译阶段不会做移除检查.int a = int.MaxValue * 2; 那么问题来了,我们当然知道checked很有用,那么uncheck呢?如果我们只是需要那么一个数而已,至于溢出不溢出的关系不大,比如说生成一个对象的HashCode,比如说根据一个算法计算出一个相对随机数,这都是不需要准确结果的,ConcurrentDictionary中对于m_keyRehashCount++这个运算就使用了unchecked,就是因为m_keyRehashCount是用来生成哈希值的,我们并不关心它有没有溢出. volatile关键字,表示一个字段可能是由在同一时间执行多个线程进行修改。出于性能原因,编译器\运行时系统甚至硬件可以重新排列对存储器位置的读取和写入。声明的字段volatile不受这些优化的约束。添加volatile修饰符可确保所有线程都能按照执行顺序由任何其他线程执行的易失性写入,易失性写入是一件疯狂的事情的事情:普通玩家慎用. 本博客所涉及的代码都保存在github中,Take it easy to enjoy it!https://github.com/liuzhenyulive/DictionaryMini/blob/master/DictionaryMini/DictionaryMini/ConcurrentDictionaryMini.cs
-
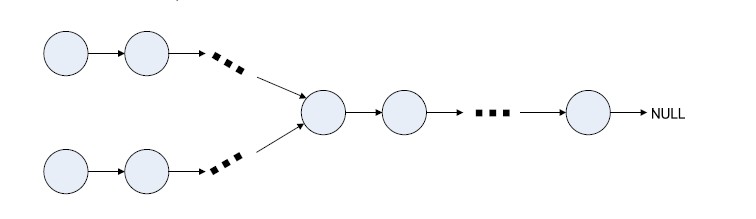
你真的了解字典(Dictionary)吗? 从一道亲身经历的面试题说起半年前,我参加我现在所在公司的面试,面试官给了一道题,说有一个Y形的链表,知道起始节点,找出交叉节点.为了便于描述,我把上面的那条线路称为线路1,下面的称为线路2.思路1先判断线路1的第一个节点的下级节点是否是线路2的第一个节点,如果不是,再判断是不是线路2的第二个,如果也不是,判断是不是第三个节点,一直到最后一个.如果第一轮没找到,再按以上思路处理线路一的第二个节点,第三个,第四个… 找到为止.时间复杂度n2,相信如果我用的是这种方法,可肯定被Pass了.思路2首先,我遍历线路2的所有节点,把节点的索引作为key,下级节点索引作为value存入字典中.然后,遍历线路1中节点,判断字典中是否包含该节点的下级节点索引的key,即dic.ContainsKey((node.next) ,如果包含,那么该下级节点就是交叉节点了.时间复杂度是n.那么问题来了,面试官问我了,为什么时间复杂度n呢?你有没有研究过字典的ContainsKey这个方法呢?难道它不是通过遍历内部元素来判断Key是否存在的呢?如果是的话,那时间复杂度还是n2才是呀?我当时支支吾吾,确实不明白字典的工作原理,厚着面皮说 “不是的,它是通过哈希表直接拿出来的,不用遍历”,面试官这边是敷衍过去了,但在我心里却留下了一个谜,已经入职半年多了,欠下的技术债是时候还了.带着问题来阅读在看这篇文章前,不知道您使用字典的时候是否有过这样的疑问. 字典为什么能无限地Add呢? 从字典中取Item速度非常快,为什么呢? 初始化字典可以指定字典容量,这是否多余呢? 字典的桶buckets 长度为素数,为什么呢? 不管您以前有没有在心里问过自己这些问题,也不管您是否已经有了自己得答案,都让我们带着这几个问题接着往下走.从哈希函数说起什么是哈希函数?哈希函数又称散列函数,是一种从任何一种数据中创建小的数字“指纹”的方法。下面,我们看看JDK中Sting.GetHashCode()方法.public int hashCode() { int h = hash; //hash default value : 0 if (h == 0 && value.length > 0) { //value : char storage char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; } 可以看到,无论多长的字符串,最终都会返回一个int值,当哈希函数确定的情况下,任何一个字符串的哈希值都是唯一且确定的.当然,这里只是找了一种最简单的字符数哈希值求法,理论上只要能把一个对象转换成唯一且确定值的函数,我们都可以把它称之为哈希函数.这是哈希函数的示意图.所以,一个对象的哈希值是确定且唯一的!.字典如何把哈希值和在集合中我们要的数据的地址关联起来呢?解开这个疑惑前我来看看一个这样不怎么恰当的例子:有一天,我不小心干了什么坏事,警察叔叔没有逮到我本人,但是他知道是一个叫阿宇的干的,他要找我肯定先去我家,他怎么知道我家的地址呢?他不可能在全中国的家庭一个个去遍历,敲门,问阿宇是你们家的熊孩子吗?正常应该是通过我的名字,找到我的身份证号码,然后我的身份证上登记着我的家庭地址(我们假设一个名字只能找到一张身份证).阿宇-----> 身份证(身份证号码,家庭住址)------>我家我们就可以把由阿宇找到身份证号码的过程,理解为哈希函数,身份证存储着我的号码的同时,也存储着我家的地址,身份证这个角色在字典中就是 bucket,它起一个桥梁作用,当有人要找阿宇家在哪时,直接问它,准备错的,字典中,bucket存储着数据的内存地址(索引),我们要知道key对应的数据的内存地址,问buckets要就对了.key—>bucket的过程 ~= 阿宇----->身份证 的过程.警察叔叔通过家庭住址找到了我家之后,我家除了住我,还住着我爸,我妈,他敲门的时候,是我爸开门,于是问我爸爸,阿宇在哪,我爸不知道,我爸便问我妈,儿子在哪?我妈告诉警察叔叔,我在书房呢.很好,警察叔叔就这样把我给逮住了.字典也是这样,因为key的哈希值范围很大的,我们不可能声明一个这么大的数组作为buckets,这样就太浪费了,我们做法时HashCode%BucketSize作为bucket的索引.假设Bucket的长度3,那么当key1的HashCode为2时,它数据地址就问buckets2要,当key2的HashCode为5时,它的数据地址也是问buckets2要的.这就导致同一个bucket可能有多个key对应,即下图中的Johon Smith和Sandra Dee,但是bucket只能记录一个内存地址(索引),也就是警察叔叔通过家庭地址找到我家时,正常来说,只有一个人过来开门,那么,如何找到也在这个家里的我的呢?我爸记录这我妈在厨房,我妈记录着我在书房,就这样,我就被揪出来了,我爸,我妈,我 就是字典中的一个entry.如果有一天,我妈妈老来得子又生了一个小宝宝,怎么办呢?很简单,我妈记录小宝宝的位置,那么我的只能巴结小宝宝,让小宝宝来记录我的位置了.既然大的原理明白了,是不是要看看源码,来研究研究代码中字典怎么实现的呢?DictionaryMini上次在苏州参加苏州微软技术俱乐部成立大会时,有幸参加了蒋金楠 老师讲的Asp .net core框架解密,蒋老师有句话让我印象很深刻,"学好一门技术的最好的方法,就是模仿它的样子,自己造一个出来"于是他弄了个Asp .net core mini,所以我效仿蒋老师,弄了个DictionaryMini其源代码我放在了Github仓库,有兴趣的可以看看:https://github.com/liuzhenyulive/DictionaryMini我觉得字典这几个方面值得了解一下: 数据存储的最小单元的数据结构 字典的初始化 添加新元素 字典的扩容 移除元素 字典中还有其他功能,但我相信,只要弄明白的这几个方面的工作原理,我们也就恰中肯綮,他么问题也就迎刃而解了.数据存储的最小单元(Entry)的数据结构 private struct Entry { public int HashCode; public int Next; public TKey Key; public TValue Value; } 一个Entry包括该key的HashCode,以及下个Entry的索引Next,该键值对的Key以及数据Vaule.字典初始化 private void Initialize(int capacity) { int size = HashHelpersMini.GetPrime(capacity); _buckets = new int[size]; for (int i = 0; i < _buckets.Length; i++) { _buckets[i] = -1; } _entries = new Entry[size]; _freeList = -1; } 字典初始化时,首先要创建int数组,分别作为buckets和entries,其中buckets的index是key的哈希值%size,它的value是数据在entries中的index,我们要取的数据就存在entries中.当某一个bucket没有指向任何entry时,它的value为-1.另外,很有意思得一点,buckets的数组长度是多少呢?这个我研究了挺久,发现取的是大于capacity的最小质数.添加新元素 private void Insert(TKey key, TValue value, bool add) { if (key == null) { throw new ArgumentNullException(); } //如果buckets为空,则重新初始化字典. if (_buckets == null) Initialize(0); //获取传入key的 哈希值 var hashCode = _comparer.GetHashCode(key); //把hashCode%size的值作为目标Bucket的Index. var targetBucket = hashCode % _buckets.Length; //遍历判断传入的key对应的值是否已经添加字典中 for (int i = _buckets[targetBucket]; i > 0; i = _entries[i].Next) { if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key)) { //当add为true时,直接抛出异常,告诉给定的值已存在在字典中. if (add) { throw new Exception("给定的关键字已存在!"); } //当add为false时,重新赋值并退出. _entries[i].Value = value; return; } } //表示本次存储数据的数据在Entries中的索引 int index; //当有数据被Remove时,freeCount会加1 if (_freeCount > 0) { //freeList为上一个移除数据的Entries的索引,这样能尽量地让连续的Entries都利用起来. index = _freeList; _freeList = _entries[index].Next; _freeCount--; } else { //当已使用的Entry的数据等于Entries的长度时,说明字典里的数据已经存满了,需要对字典进行扩容,Resize. if (_count == _entries.Length) { Resize(); targetBucket = hashCode % _buckets.Length; } //默认取未使用的第一个 index = _count; _count++; } //对Entries进行赋值 _entries[index].HashCode = hashCode; _entries[index].Next = _buckets[targetBucket]; _entries[index].Key = key; _entries[index].Value = value; //用buckets来登记数据在Entries中的索引. _buckets[targetBucket] = index; } 字典的扩容private void Resize() { //获取大于当前size的最小质数 Resize(HashHelpersMini.GetPrime(_count), false); } private void Resize(int newSize, bool foreNewHashCodes) { var newBuckets = new int[newSize]; //把所有buckets设置-1 for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1; var newEntries = new Entry[newSize]; //把旧的的Enties中的数据拷贝到新的Entires数组中. Array.Copy(_entries, 0, newEntries, 0, _count); if (foreNewHashCodes) { for (int i = 0; i < _count; i++) { if (newEntries[i].HashCode != -1) { newEntries[i].HashCode = _comparer.GetHashCode(newEntries[i].Key); } } } //重新对新的bucket赋值. for (int i = 0; i < _count; i++) { if (newEntries[i].HashCode > 0) { int bucket = newEntries[i].HashCode % newSize; newEntries[i].Next = newBuckets[bucket]; newBuckets[bucket] = i; } } _buckets = newBuckets; _entries = newEntries; } 移除元素 //通过key移除指定的item public bool Remove(TKey key) { if (key == null) throw new Exception(); if (_buckets != null) { //获取该key的HashCode int hashCode = _comparer.GetHashCode(key); //获取bucket的索引 int bucket = hashCode % _buckets.Length; int last = -1; for (int i = _buckets[bucket]; i >= 0; last = i, i = _entries[i].Next) { if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key)) { if (last < 0) { _buckets[bucket] = _entries[i].Next; } else { _entries[last].Next = _entries[i].Next; } //把要移除的元素置空. _entries[i].HashCode = -1; _entries[i].Next = _freeList; _entries[i].Key = default(TKey); _entries[i].Value = default(TValue); //把该释放的索引记录在freeList中 _freeList = i; //把空Entry的数量加1 _freeCount++; return true; } } } return false; } 我对.Net中的Dictionary的源码进行了精简,做了一个DictionaryMini,有兴趣的可以到我的github查看相关代码.https://github.com/liuzhenyulive/DictionaryMini答疑时间字典为什么能无限地Add呢向Dictionary中添加元素时,会有一步进行判断字典是否满了,如果满了,会用Resize对字典进行自动地扩容,所以字典不会向数组那样有固定的容量.为什么从字典中取数据这么快Key–>HashCode–>HashCode%Size–>Bucket Index–>Bucket–>Entry Index–>Value整个过程都没有通过遍历来查找数据,一步到下一步的目的性时非常明确的,所以取数据的过程非常快.初始化字典可以指定字典容量,这是否多余呢前面说过,当向字典中插入数据时,如果字典已满,会自动地给字典Resize扩容.扩容的标准时会把大于当前前容量的最小质数作为当前字典的容量,比如,当我们的字典最终存储的元素为15个时,会有这样的一个过程.new Dictionary()------------------->size:3字典添加低3个元素---->Resize—>size:7字典添加低7个元素---->Resize—>size:11字典添加低11个元素—>Resize—>size:23可以看到一共进行了三次次Resize,如果我们预先知道最终字典要存储15个元素,那么我们可以用new Dictionary(15)来创建一个字典.new Dictionary(15)---------->size:23这样就不需要进行Resize了,可以想象,每次Resize都是消耗一定的时间资源的,需要把OldEnties Copy to NewEntries 所以我们在创建字典时,如果知道字典的中要存储的字典的元素个数,在创建字典时,就传入capacity,免去了中间的Resize进行扩容.Tips:即使指定字典容量capacity,后期如果添加的元素超过这个数量,字典也是会自动扩容的.为什么字典的桶buckets 长度为素数我们假设有这样的一系列keys,他们的分布范围时K={ 0, 1,…, 100 },又假设某一个buckets的长度m=12,因为3是12的一个因子,当key时3的倍数时,那么targetBucket也将会是3的倍数. Keys {0,12,24,36,...} TargetBucket将会是0. Keys {3,15,27,39,...} TargetBucket将会是3. Keys {6,18,30,42,...} TargetBucket将会是6. Keys {9,21,33,45,...} TargetBucket将会是9. 如果Key的值是均匀分布的(K中的每一个Key中出现的可能性相同),那么Buckets的Length就没有那么重要了,但是如果Key不是均匀分布呢?想象一下,如果Key在3的倍数时出现的可能性特别大,其他的基本不出现,TargetBucket那些不是3的倍数的索引就基本不会存储什么数据了,这样就可能有2/3的Bucket空着,数据大量第聚集在0,3,6,9中.这种情况其实时很常见的。 例如,又一种场景,您根据对象存储在内存中的位置来跟踪对象,如果你的计算机的字节大小是4,而且你的Buckets的长度也为4,那么所有的内存地址都会时4的倍数,也就是说key都是4的倍数,它的HashCode也将会时4的倍数,导致所有的数据都会存储在TargetBucket=0(Key%4=0)的bucket中,而剩下的3/4的Buckets都是空的. 这样数据分布就非常不均匀了.K中的每一个key如果与Buckets的长度m有公因子,那么该数据就会存储在这个公因子的倍数为索引的bucket中.为了让数据尽可能地均匀地分布在Buckets中,我们要尽量减少m和K中的key的有公因子出现的可能性.那么,把Bucket的长度设为质数就是最佳选择了,因为质数的因子时最少的.这就是为什么每次利用Resize给字典扩容时会取大于当前size的最小质数的原因.确实,这一块可能有点难以理解,我花了好几天才研究明白,如果小伙伴们没有看懂建议看看这里.https://cs.stackexchange.com/questions/11029/why-is-it-best-to-use-a-prime-number-as-a-mod-in-a-hashing-function/64191#64191最后,感谢大家耐着性子把这篇文章看完,欢迎fork DictionaryMini进行进一步的研究,谢谢大家的支持.https://github.com/liuzhenyulive/DictionaryMini
-
轻量级.Net Core服务注册工具CodeDi发布啦 为什么做这么一个工具因为我们的系统往往时面向接口编程的,所以在开发Asp .net core项目的时候,一定会有大量大接口及其对应的实现要在ConfigureService注册到ServiceCollection中,传统的做法是加了一个服务,我们就要注册一次(service.AddService()),又比如,当一个接口有多个实现,在构造函数中获取服务也不是很友好,而据我所知, .Net Core目前是没有什么自带的库或者方法解决这些问题,当然,如果引入第三方容器如AutoFac这些问题时能迎刃而解的,但是如何在不引入第三方容器来解决这个问题呢?所以我就设计了这样的一个轻量级工具.首先,放上该项目的Github地址(记得Star哦!!)https://github.com/liuzhenyulive/CodeDiCodeDi是一个基于 .Net Standard的工具库,它能帮助我们自动地在Asp .net core或者 .net core项目中完成服务的注册.OverviewCodeDi 是 Code Dependency Injection的意思,在上次我在看了由依乐祝写的<.NET Core中的一个接口多种实现的依赖注入与动态选择看这篇就够了>后,回想起我之前遇到的那些问题,感觉拨云见日,所以,我就开始着手写这个工具了.如何使用CodeDi安装Nuget包CodeDi的Nuget包已经发布到了 nuget.org,您可以通过以下指令在您的项目中安装CodeDiPM> Install-Package CodeDi ConfigureServices中的配置方法 1您可以在Startup的ConfigureService方法中添加AddCodeDi完成对CodeDi的调用.服务的注册CodeDi会自动为您完成. public void ConfigureServices(IServiceCollection services) { services.AddCoreDi(); services.AddMvc(); } 方法 2您也可以在AddCodeDi方法中传入一个Action<CodeDiOptions>参数,在这个action中,您可以对CodeDiOptions的属性进行配置. public void ConfigureServices(IServiceCollection services) { services.AddCoreDi(options => { options.DefaultServiceLifetime = ServiceLifetime.Scoped; }); services.AddMvc(); } 方法 3当然您也可以直接给AddCodeDi()方法直接传入一个CodeDiOptions实例. public void ConfigureServices(IServiceCollection services) { services.AddCoreDi(new CodeDiOptions() { DefaultServiceLifetime = ServiceLifetime.Scoped }); services.AddMvc(); } 你也可以在appsetting.json文件中配置CodeDiOptions的信息,并通过Configuration.Bind("CodeDiOptions", options)把配置信息绑定到一个CodeDiOptions实例.appsetting.json file{ "Logging": { "LogLevel": { "Default": "Warning" } }, "AllowedHosts": "*", "CodeDiOptions": { "DefaultServiceLifetime": 1, "AssemblyNames": [ "*CodeDi" ], "AssemblyPaths": [ "C:\\MyBox\\Github\\CodeDI\\CodeDI\\bin\\Debug\\netstandard2.0" ], "IgnoreAssemblies": [ "*Test" ], "IncludeSystemAssemblies": false, "IgnoreInterface": [ "*Say" ], "InterfaceMappings": { "*Say": "*English" }, "ServiceLifeTimeMappings": { "*Say": 0 } } } ConfigureService方法 public void ConfigureServices(IServiceCollection services) { var options=new CodeDiOptions(); Configuration.Bind("CodeDiOptions", options); services.AddCoreDi(options); services.AddMvc(); } CodeDiOptions详解 属性名称 属性描述 数据类型 默认值 AssemblyPaths 在指定目录下加载Dll程序集 string[] Bin目录 AssemblyNames 选择要加载的程序集名称 (支持通配符) string[] * IgnoreAssemblies 忽略的程序集名称 (支持通配符) string[] null IncludeSystemAssemblies 是否包含系统程序集(当为false时,会忽略含有System,Microsoft,CppCodeProvider,WebMatrix,SMDiagnostics,Newtonsoft关键词和在App_Web,App_global目录下的程序集) bool false IgnoreInterface 忽略的接口 (支持通配符) string[] null InterfaceMappings 接口对应的服务 (支持通配符) ,当一个接口有多个实现时,如果不进行配置,则多个实现都会注册到SerciceCollection中 Dictionary<string, string> null DefaultServiceLifetime 默认的服务生命周期 ServuceLifetime( Singleton,Scoped,Transient) ServiceLifetime.Scope ServiceLifeTimeMappings 指定某个接口的服务生命周期,不指定为默认的生命周期 Dictionary<string, ServiceLifetime> null InterfaceMappings如果 ISay 接口有SayInChinese 和SayInEnglish 两个实现,我们只想把SayInEnglish注册到ServiceCollection中 public interface ISay { string Hello(); } public class SayInChinese:ISay { public string Hello() { return "您好"; } } public class SayInEnglish:ISay { public string Hello() { return "Hello"; } } 那么我们可以这样配置InterfaceMappings.options.InterfaceMappings=new Dictionary<string, string>(){{ “ISay”, “SayInChinese” } }也就是{接口名称(支持通配符),实现名称(支持通配符)}ServiceLifeTimeMappings如果我们希望ISay接口的服务的生命周期为Singleton,我们可以这样配置ServiceLifeTimeMappings.options.ServiceLifeTimeMappings = new Dictionary<string, ServiceLifetime>(){{“*Say”,ServiceLifetime.Singleton}};也就是也就是{接口名称(支持通配符),Servicelifetime}关于ServiceLifetime: https://github.com/aspnet/DependencyInjection/blob/master/src/DI.Abstractions/ServiceLifetime.cs获取服务实例当然, 您可以和之前一样,直接在构造函数中进行依赖的注入,但是当某个接口有多个实现而且都注册到了ServiceCollection中,获取就没有那么方便了,您可以用ICodeDiServiceProvider 来帮助您获取服务实例.例如,当 ISay 接口有 SayInChinese 和 SayInEnglish两个实现, 我们我们如何获取我们想要的服务实例呢? public interface ISay { string Hello(); } public class SayInChinese:ISay { public string Hello() { return "您好"; } } public class SayInEnglish:ISay { public string Hello() { return "Hello"; } } public class HomeController : Controller { private readonly ISay _say; public HomeController(ICodeDiServiceProvider serviceProvider) { _say = serviceProvider.GetService<ISay>("*Chinese"); } public string Index() { return _say.Hello(); } } ICodeDiServiceProvider.GetService<T>(string name=null)参数中的Name支持通配符.CodeDi如何实现的?既然是一个轻量级工具,那么实现起来自然不会太复杂,我来说说比较核心的代码. private Dictionary<Type, List<Type>> GetInterfaceMapping(IList<Assembly> assemblies) { var mappings = new Dictionary<Type, List<Type>>(); var allInterfaces = assemblies.SelectMany(u => u.GetTypes()).Where(u => u.IsInterface); foreach (var @interface in allInterfaces) { mappings.Add(@interface, assemblies.SelectMany(a => a.GetTypes(). Where(t => t.GetInterfaces().Contains(@interface) ) ) .ToList()); } return mappings; } GetInterfaceMapping通过反射机制,首先获取程序集中的所有接口allInterfaces,然后遍历allInterfaces找到该接口对应的实现,最终,该方法返回接口和实现的匹配关系,为Dictionary<Type, List>类型的数据. private void AddToService(Dictionary<Type, List<Type>> interfaceMappings) { foreach (var mapping in interfaceMappings) { if (mapping.Key.FullName == null || (_options.IgnoreInterface != null && _options.IgnoreInterface.Any(i => mapping.Key.FullName.Matches(i)))) continue; if (mapping.Key.FullName != null && _options.InterfaceMappings != null && _options.InterfaceMappings.Any(u => mapping.Key.FullName.Matches(u.Key))) { foreach (var item in mapping.Value.Where(value => value.FullName != null). Where(value => value.FullName.Matches(_options.InterfaceMappings.FirstOrDefault(u => mapping.Key.FullName.Matches(u.Key)).Value))) { AddToService(mapping.Key, item); } continue; } foreach (var item in mapping.Value) { AddToService(mapping.Key, item); } } } 该方法要判断CodeDiOptions中是否忽略了该接口,同时,是否指定实现映射关系.什么叫实现映射关系呢?参见InterfaceMappings如果指定了,那么就按指定的来实现,如果没指定,就会把每个实现都注册到ServiceCollection中. private readonly IServiceCollection _service; private readonly CodeDiOptions _options; private readonly ServiceDescriptor[] _addedService; public CodeDiService(IServiceCollection service, CodeDiOptions options) { _service = service ?? throw new ArgumentNullException(nameof(service)); _options = options ?? new CodeDiOptions(); _addedService = new ServiceDescriptor[service.Count]; service.CopyTo(_addedService, 0); //在构造函数中,我们通过这种方式把Service中已经添加的服务读取出来 //后面进行服务注册时,会进行判断,避免重复添加 } private void AddToService(Type serviceType, Type implementationType) { ServiceLifetime serviceLifetime; try { serviceLifetime = _options.DefaultServiceLifetime; if (_options.ServiceLifeTimeMappings != null && serviceType.FullName != null) { var lifeTimeMapping = _options.ServiceLifeTimeMappings.FirstOrDefault(u => serviceType.FullName.Matches(u.Key)); serviceLifetime = lifeTimeMapping.Key != null ? lifeTimeMapping.Value : _options.DefaultServiceLifetime; } } catch { throw new Exception("Service Life Time Only Can be set in range of 0-2"); } if (_addedService.Where(u => u.ServiceType == serviceType).Any(u => u.ImplementationType == implementationType)) return; _service.Add(new ServiceDescriptor(serviceType, implementationType, serviceLifetime)); } AddToService中,要判断有没有对接口的生命周期进行配置,参见ServiceLifeTimeMappings,如果没有配置,就按DefaultServiceLifetime进行配置,DefaultServiceLifetime如果没有修改的情况下时ServiceLifetime.Scoped,即每个Request创建一个实例. private readonly IServiceProvider _serviceProvider; public CodeDiServiceProvider(IServiceProvider serviceProvider) { _serviceProvider = serviceProvider; } public T GetService<T>(string name) where T : class { return _serviceProvider.GetService<IEnumerable<T>>().FirstOrDefault(u => u.GetType().Name.Matches( name)); } 这CodeDiServiceProvider的实现代码,这里参考了依乐祝写的<.NET Core中的一个接口多种实现的依赖注入与动态选择看这篇就够了>给出的一种解决方案,即当某个接口注册了多个实现,其实可以通过IEnumerable获取所有的实现,CodeDiServiceProvider对其进行了封装.Enjoy it只要进行一次简单的CodeDi配置,以后系统中添加了新的接口以及对应的服务实现后,就不用再去一个个地Add到IServiceCollection中了.如果有问题,欢迎Issue,欢迎PR.最后,赏个Star呗! 前往Star